
With the outbreak of generative AI and chatbots, the curiosity in LLMs has quickly grown within the final couple of years. Nonetheless, RLHF has seen comparatively much less development (Determine 1). Regardless of its spectacular ends in the event of AI, generative AI, and LLMs, RLHF is a comparatively new strategy that many individuals nonetheless don’t learn about.
To fill this data hole, this text explores the connection between the 2 abbreviations, how RLHF advantages giant language fashions, and gives a comparability of the highest RLHF service suppliers.
Determine 1. The worldwide on-line curiosity between RLHF and LLMs

What’s RLHF (Reinforcement Studying with Human Suggestions)?
Reinforcement studying, or RL, is a machine studying strategy the place algorithms study by receiving suggestions, sometimes within the type of a reward perform. The normal methodology entails coaching a mannequin to foretell the absolute best motion in a given situation primarily based on an automatic reward system.
RLHF takes this a step additional by including people to the training course of. It entails the mixing of human suggestions into the reward system. By incorporating human suggestions, the machine studying mannequin will get refined instructions, adjusting its habits primarily based on human choice knowledge.
How does it work?
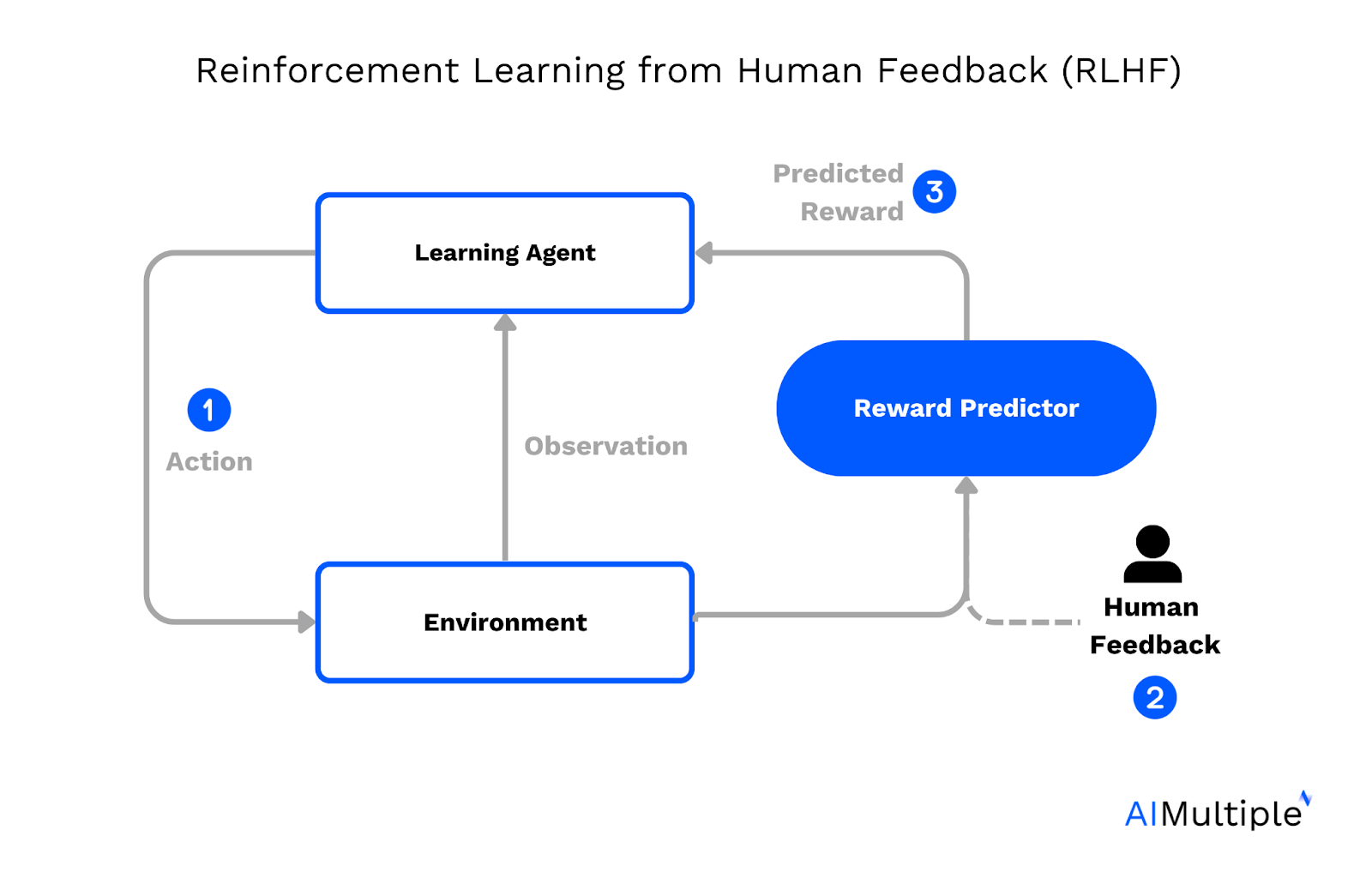
On the coronary heart of the RLHF coaching course of is the reward mannequin. As a substitute of relying solely on predefined standards, it incorporates suggestions from people within the studying course of.
A simplified clarification would contain two language fashions: an preliminary language mannequin that generates textual content outputs and a barely modified model. Human reviewers would then rank the standard of generated textual content outputs from each fashions.
This human-generated textual content comparability aids the automated system in understanding which outputs are extra fascinating, enabling the reward mannequin to evolve.
It’s a dynamic course of, with each human suggestions and the reward mannequin evolving collectively to information the machine-learning strategy.
Determine 2. Reinforcement studying with human suggestions course of stream
What are LLMs (giant language fashions)?
Giant language fashions, or LLMs, are on the forefront of the AI and machine studying revolution in pure language processing. These machine-learning fashions are designed to know and generate textual content, simulating human-like dialog capabilities.
LLMs are constructed on huge quantities of textual content knowledge, present process rigorous coaching processes. Their energy is obvious of their capability to supply coherent and contextually related textual content primarily based on the preliminary coaching knowledge they’ve been offered.
How are they skilled?
Coaching giant language fashions isn’t any small feat. It begins with an preliminary language mannequin constructed on a various set of coaching knowledge. This pre-trained language mannequin is then fine-tuned primarily based on particular duties or domains.
Given the complexity of human language and pure language processing, it’s essential that such fashions endure a number of iterations of refinement. Whereas these fashions can study from huge quantities of knowledge, the true problem lies in guaranteeing they generate correct and nuanced responses. That’s the place RLHF comes into play.
Sponsored
Clickworker presents RLHF providers for LLMs through a crowdsourcing platform. Its international community of over 4.5 million employees serves 4 out of 5 tech giants within the U.S. Clickworker additionally focuses on making ready coaching knowledge for LLMs and different AI techniques, together with:
- Producing and accumulating picture, audio, video, and textual content knowledge
- Performing RLHF providers
- Processing datasets for machine studying
- Conducting analysis and surveys
- Conducting sentiment evaluation.
How can the RLHF method profit LLMs?
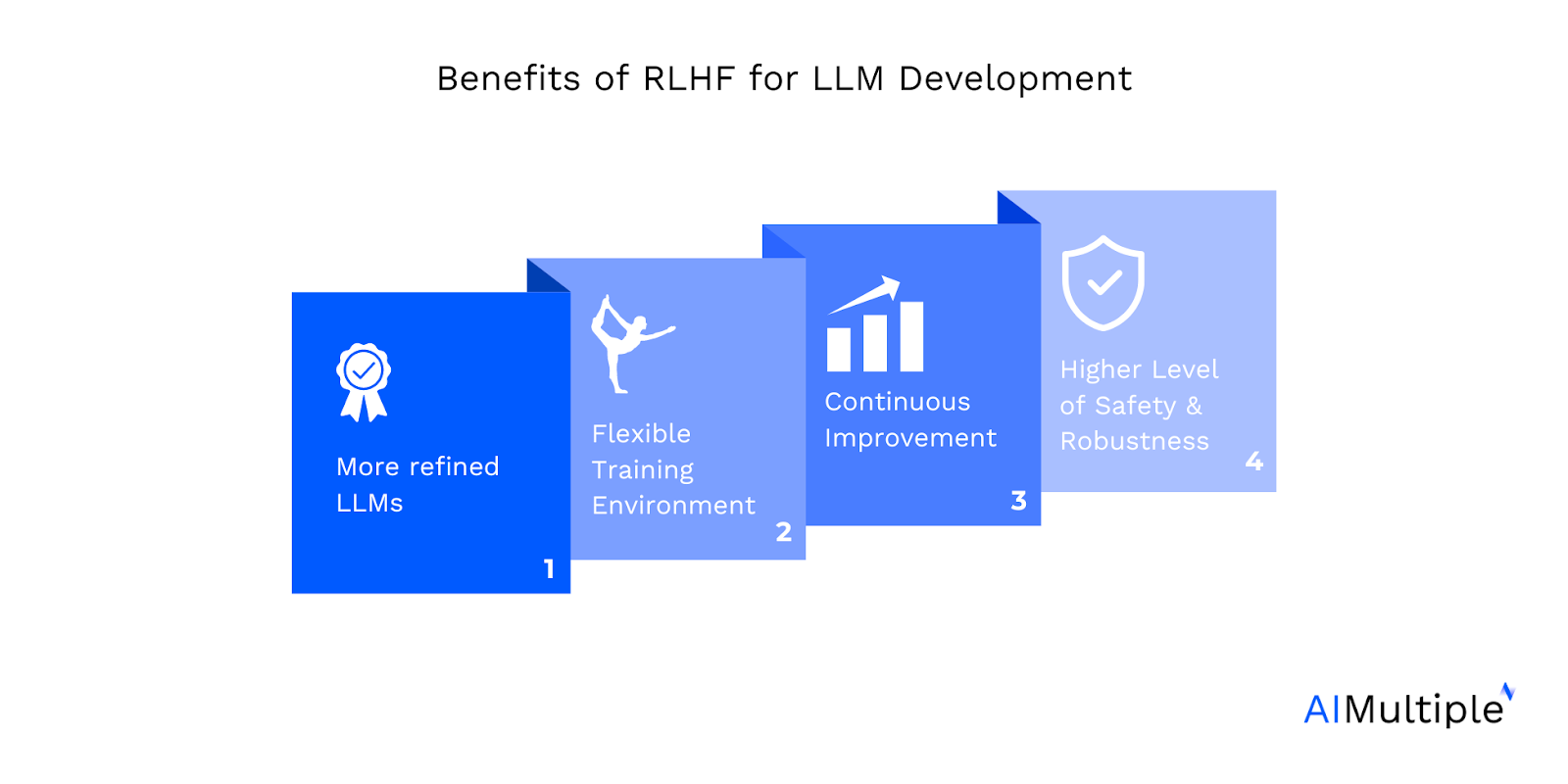
The symbiotic relationship between RLHF and LLMs has modified the sport in AI-driven language processing. Let’s discover how.
1. Extra refined LLMs
Within the RLHF paradigm, an preliminary mannequin is skilled utilizing conventional strategies. This mannequin, whereas highly effective, nonetheless has room for enchancment. By introducing human suggestions integration, the mannequin is refined primarily based on human-provided reward indicators.
The method entails coaching the LLM utilizing reward features derived from human suggestions. This not solely refines the mannequin parameters however ensures the mannequin aligns extra intently with human conversational norms.
2. Versatile coaching setting
As a substitute of a static, pre-defined reward system, the dynamic human-augmented reward mannequin creates a versatile coaching setting. When the mannequin generates textual content, the suggestions doesn’t simply have a look at the correctness however evaluates nuances, context, and relevance. Such an strategy ensures that the generated textual content outputs are usually not simply technically proper however are contextually and emotionally aligned.
3. Steady enchancment
The RLHF strategy shouldn’t be a one-off course of. The reward mannequin retains evolving, taking in increasingly more nuanced human suggestions. This steady evolution ensures that as language developments change and new linguistic nuances emerge, the massive language mannequin stays up to date and related.
4. Greater degree of security and robustness
Utilizing RLHF permits builders to determine and deal with unintended mannequin behaviors. By receiving human suggestions, potential points, biases, or inaccuracies within the mannequin’s outputs might be corrected, guaranteeing the mannequin’s responses are safer and extra dependable. This interactive strategy ensures a extra sturdy mannequin that’s much less vulnerable to errors or controversial outputs.
Why work with an RLHF service supplier to develop LLMs?
Creating LLMs could be a resource-heavy and labor-intensive course of if achieved in-house. Working with an RLHF service supplier can provide numerous advantages to your giant language mannequin growth course of.
1. Experience in human suggestions integration
RLHF service suppliers herald a deep understanding of the way to successfully combine human suggestions into the coaching course of. Their experience ensures that the suggestions generated by human contributors isn’t just integrated however is used optimally to information the AI’s studying.
2. Environment friendly reward perform creation
Provided that reward features play a pivotal position within the RLHF course of, an RLHF service supplier’s experience ensures these features are exact, related, and efficient. They bridge the hole between the LLM’s understanding of language and human conversational norms.
3. Scalability and steady refinement
Working with an RLHF accomplice ensures that the LLM doesn’t simply get preliminary refinement however undergoes steady enchancment. Such partnerships present an infrastructure the place common human suggestions, each constructive and detrimental, is fed into the system, guaranteeing the mannequin stays top-notch.
4. Extra range
RLHF service suppliers normally work with a crowdsourcing platform or a big community of employees. This will be sure that the suggestions the mannequin receives is diverse and encompasses a variety of human experiences and views.
By tapping into reviewers from completely different areas and cultures, an outsourced strategy can assist in coaching a mannequin that’s extra globally conscious. That is particularly vital for LLMs that should serve a worldwide viewers, guaranteeing they don’t mirror only a single regional or cultural perspective.
Evaluating the highest RLHF service supplier in the marketplace
This part compares the highest RLHF service suppliers in the marketplace.
Desk 1. Comparability of the market presence class
| Firm | Crowd measurement | Share of shoppers amongst prime 5 consumers | Buyer Opinions |
|---|---|---|---|
| Clickworker | 4.5M+ | 80% | – G2: 3.9 – Trustpilot: 4.4 – Capterra: 4.4 |
| Appen | 1M+ | 60% | – G2: 4.3 – Capterra: 4.1 |
| Prolific | 130K+ | 40% | – G2: 4.3 – Trustpilot: 2.7 |
| Surge AI | N/A | 60% | N/A |
| Toloka AI | 245k+ | 20% | – Trustpilot: 2.8 – Capterra: 4.0 |
Desk 2: Comparability of the characteristic set class
| Firm | Cell software | API availability | ISO 27001 Certification | Code of Conduct | GDPR Compliance |
|---|---|---|---|---|---|
| Clickworker | TRUE | TRUE | TRUE | TRUE | TRUE |
| Appen | TRUE | TRUE | TRUE | TRUE | TRUE |
| Prolific | FALSE | TRUE | FALSE | TRUE | TRUE |
| Surge AI | FALSE | TRUE | TRUE | FALSE | FALSE |
| Toloka AI | TRUE | TRUE | TRUE | TRUE | TRUE |
Notes & observations from the tables:
- The corporate choice standards will probably be up to date because the market, and our understanding of the market evolves.
- The knowledge on the corporate’s capabilities was not verified. A service supplier is assumed to supply a functionality if that functionality is talked about of their providers web page or case research as of Aug/2023. We might confirm firms’ statements sooner or later.
- The corporate’s capabilities weren’t quantitatively measured. We checked if capabilities had been supplied or not. In a benchmarking train with merchandise, quantitative metrics might be launched sooner or later.
- All knowledge added to the tables is predicated on firm claims.
- The businesses chosen on this comparability had been primarily based on the relevance of their providers.
- All service suppliers provide API integration capabilities.
Tips on how to discover the suitable RLHF service supplier on your challenge?
This part lists the factors we used to pick the RLHF service suppliers in contrast on this article. The readers can even use this criterion to seek out the suitable match for his or her enterprise. The standards is split into 2 classes:
- Market presence
- Function Set
Market presence
1. Share of shoppers amongst prime 5 consumers
To know the corporate’s market footprint and get perception into its relevance and dominance out there, study its clientele amongst these prime 5 tech giants:
- Samsung
- Apple
- Microsoft
- Meta
2. Consumer evaluations
Verify evaluations on G2 and Trustpilot for insights into the corporate’s efficiency. Guarantee evaluations match the precise service you’re contemplating since firms provide diverse providers.
Function set
3. Platform Options
Study the service supplier’s capabilities. Do they supply a cell app or API integration?
4. Information safety practices
Given the rise in cyber threats, sturdy knowledge safety is important. We seemed for ISO 27001 certification and GDPR compliance.
5. Fairtrade
Your accomplice’s ethics have an effect on your fame. Guarantee they uphold honest practices for employees.
Additional studying
In the event you need assistance discovering a vendor or have any questions, be happy to contact us:
Discover the Proper Distributors