


- For a complete listing of all of the papers and articles of this collection examine our Git repo. Nevertheless, should you favor a e-book with curated content material in order to begin constructing your individual fancy GANs, begin from the “GANs in Motion” e-book!
Whats is generative studying? What’s a GAN? Why can we use it? What’s the distinction with autoencoders? What’s the elementary coaching algorithm of a GAN mannequin? How can we make it study significant representations? In what pc imaginative and prescient utility can it’s helpful? How can one design one for her/his drawback?
We are going to handle all these questions and far a lot! On this overview article collection, we are going to give attention to a plethora of GANs for pc imaginative and prescient functions. Particularly, we are going to slowly construct upon the concepts and the ideas that led to the evolution of generative adversarial networks (GAN). We are going to encounter completely different duties similar to conditional picture technology, 3D object technology, video synthesis.
Let’s begin with reviewing our contents of the primary half!
On the whole, knowledge technology strategies exist in a wide selection of recent deep studying functions, from pc imaginative and prescient to pure language processing. At this level, we’re capable of produce practically indistinguishable generative knowledge by the human eye. Generative studying will be broadly divided into two fundamental classes: a) Variational AutoEncoders (VAE) and b) generative adversarial networks (GAN).
Why not simply autoencoders?
Lots of people are nonetheless questioning why researchers make issues so troublesome with GANs. Why don’t simply use an autoencoder and decrease the imply squared error, having the goal picture to match the expected one? The reason being that these fashions produce poor outcomes (for picture technology). Really, simply minimizing the space produces blurry predictions due to the averaging. Keep in mind the L1 or L2 loss is scalar, which is a mean amount of all of the pixels. Intuitively, it’s a related idea as making use of a smoothing filter that averages the pixel values primarily based on the common. Second, it’s unattainable to supply range in such a method (like variational autoencoders). That’s why the eye of the analysis group adopted GAN fashions. Remember that that is not a comparability however a differentiation of the GAN strategy.
So, let’s begin from the very starting: what’s adversarial studying anyway?
What’s adversarial studying?
We now have experimentally validated that deep studying fashions are extremely susceptible to assaults which can be primarily based on small modifications of the enter to the mannequin at check time. Suppose you’ve a skilled classifier that accurately acknowledges an object in a picture with the proper label.
It’s doable to assemble an adversarial instance, which is a visually indistinguishable picture. These adversarial pictures will be constructed by noise perturbation. Nevertheless, the picture is assessed incorrectly. To handle this drawback, a standard strategy is to inject adversarial examples into the coaching set (adversarial coaching). Therefore, the neural community’s robustness will be elevated. This sort of instance will be generated by including noise, by making use of knowledge augmentation strategies or by perturbating the picture in the wrong way of the gradient (to maximise loss as an alternative of minimizing it). However, a majority of these strategies are just a little bit hand-crafted so there’ll at all times be a unique perturbation that may be utilized to idiot our classifier. Now let’s suppose the opposite method round!
What if we aren’t desirous about having a sturdy classifier, however relatively we’re desirous about changing the hand-crafted process of adversarial examples? On this method, we are able to let the community create completely different examples which can be visually interesting. So, that’s precisely the place the generative time period comes into play. We give attention to producing consultant examples of the dataset as an alternative of creating the community extra sturdy to perturbations! Allow us to use one other community to do that work for us. How would you name a community that generates real looking examples much like the coaching ones? Generator, after all!
Vanilla GAN (Generative Adversarial Networks 2014)
Generator
Since a generator is solely a neural community, we have to present it with an enter and resolve what the output will likely be. Within the easiest kind, the enter is random noise that’s sampled from a distribution in a small vary of actual numbers. That is what we name latent or steady area. Nevertheless, since I exploit the phrase random it implies that each time I pattern from a random distribution, I’ll get a unique vector pattern. That’s what stochasticity is all about. Such enter will present us with a non-deterministic output. As a consequence, there isn’t any restrict to the variety of samples we are able to generate! Stochasticity can be the rationale why you see the image of anticipated worth within the papers associated to Generative Adversarial Studying (GAN). The output will likely be a generated picture for picture technology or one thing that we wish to generate. The principle distinction is that now we give attention to producing consultant examples of a particular distribution (i.e. canine, work, road footage, airplanes, and many others.)
Now, what concerning the discriminator?
Discriminator
The discriminator is nothing greater than the classifier. Nevertheless, as an alternative of classifying a picture within the appropriate class, we give attention to studying the distribution of the category (let’s say producing constructing pictures). Due to this fact, for the reason that desired class is thought, we wish the classifier to quantify how consultant the category is to the true class distribution. That’s why discriminators output a single chance, whereby 0 corresponds to the pretend generated pictures and 1 to the true samples from our distribution.
An excellent generator would produce indistinguishable examples which implies an output of 0.5. By way of sport principle, this adversary is named a 2-player minmax sport. In sport principle, a min-max sport or Nash equilibrium is a mathematical illustration of a non-cooperative sport involving two gamers, by which every participant is assumed to know the equilibrium methods of the opposite participant, and no participant has something to realize by altering solely their very own technique.
Generator G makes an attempt to supply pretend examples which can be near the true distribution in order to idiot Discriminator D, whereas D tries to resolve the origin of the distribution. The core concept that guidelines GANs relies on the “oblique” coaching by means of D that can be getting up to date dynamically.
The generative adversarial coaching scheme
Based mostly on the above ideas, the primary GAN was launched in 2014. It is very important perceive the coaching technique of generative studying. One key perception is the oblique coaching: this mainly implies that the generator is just not skilled to reduce the space to a particular picture, however simply to idiot the discriminator! This permits the mannequin to study in an unsupervised method. Lastly, concentrate that the bottom fact when coaching the generator is 1 (like an actual picture) within the output, despite the fact that the examples are pretend. This occurs as a result of our goal is simply to idiot D. The picture beneath illustrates this course of:
An illustration of the generator coaching scheme
Alternatively, the discriminator makes use of the true picture and the generated to tell apart them, pushing the prediction of the true picture to 1(actual) and the prediction of the generated picture to 0 (pretend). On this stage, discover that the Generator is just not skilled.

An illustration of the discriminator coaching scheme
The authors of GAN proposed an structure consisting of 4 fully-connected layers for each G and D. After all, G outputs a 1-D vector of the picture and D outputs a scalar within the vary (0,1).
GAN coaching scheme in motion
Illustration offers us energy over concepts. It’s good to know the mathematics earlier than seeing the code. So, given discriminator D, generator G, vale operate V the basic two-player minimax sport will be outlined as (M are the samples):
In follow, recalling the discete definition of the anticipated worth, it appears to be like like this:
In reality, the discriminator performs gradient ascend, whereas the generator performs gradient descent. This may be noticed by inspecting the variations within the generator a part of the above equations. Word that, D must entry each actual and pretend knowledge, whereas G has no entry to the true pictures. Let’s see this lovely but wonderful concept in follow in actual python code:
import torch
def ones_target(measurement):
'''
For actual knowledge when coaching D, whereas for pretend knowledge when coaching G
Tensor containing ones, with form = measurement
'''
return torch.ones(measurement, 1)
def zeros_target(measurement):
'''
For knowledge when coaching D
Tensor containing zeros, with form = measurement
'''
return torch.zeros(measurement, 1)
def train_discriminator(discriminator, optimizer, real_data, fake_data, loss):
N = real_data.measurement(0)
optimizer.zero_grad()
prediction_real = discriminator(real_data)
target_real = ones_target(N)
error_real = loss(prediction_real, target_real)
error_real.backward()
prediction_fake = discriminator(fake_data)
target_fake = zeros_target(N)
error_fake = loss(prediction_fake, target_fake)
error_fake.backward()
optimizer.step()
return error_real + error_fake, prediction_real, prediction_fake
def train_generator(discriminator, optimizer, fake_data, loss):
N = fake_data.measurement(0)
optimizer.zero_grad()
prediction = discriminator(fake_data)
goal = ones_target(N)
error = loss(prediction, goal)
error.backward()
optimizer.step()
return error
Now, let’s see some generated pictures. Picture change corresponds to a unique epoch.
 Generated Vanilla GAN pictures in Mnist
Generated Vanilla GAN pictures in Mnist
Mode collapse in GANs
On the whole, GANs are susceptible to the so-called mode collapse drawback. The latter normally refers back to the generator that fails to adequately symbolize the pixel-space of all of the doable outputs. As an alternative, G selects just some restricted influential modes that correspond to noise pictures. On this method, D is ready to distinguish actual from fakes and the lack of the G will get extremely unstable (on account of exploding gradients). We are going to revisit mode collapse a number of occasions in our collection, thus it’s essential to know the essential precept.
Principally, G stucks in a parameter setting the place it at all times emits the identical level. After collapse has occurred, the discriminator learns that this single level comes from the generator, however gradient descent is unable to separate the equivalent outputs. Because of this, the gradients of D push the one level produced by the generator round area ceaselessly.
Mode collapse might occur the opposite method round: If whereas coaching the discriminator will get caught in an area minimal and he’s not capable of finding one of the best technique, then it is too simple for the generator to idiot the present discriminator (in a few iterations).
Lastly, I’d clarify mode collapse in easy phrases as: the state of the 2-player sport the place one of many gamers beneficial properties an nearly irreversible benefit, which makes it troublesome to lose the sport.
Conditional GAN (Conditional Generative Adversarial Nets 2014)
Conditional chance is a measure of the chance of an occasion occurring on condition that one other occasion has occurred. On this work, the conditional model of GAN is launched. Principally, conditional data will be utilized by merely feeding no matter “additional” knowledge, similar to picture tags/labels, and many others. By conditioning the mannequin on auxiliary data, it’s doable to information the information technology course of.
Based mostly on the technology job, one can carry out the conditioning by feeding data into each D and G, as further enter through concatenation. In different domains similar to medical picture technology, the situation could also be demographic data (i.e. age, top) or semantic segmentation.

Visible illustration of conditioning a GAN taken from cGAN paper
DCGAN (Unsupervised Illustration Studying with Deep Convolutional Generative Adversarial Networks 2015)
DCGAN was the primary convolutional GAN. Deep Convolutional Generative Adversarial Nets (DCGAN) is a topologically constrained variant of GAN. As a way to scale back the variety of parameters per layer, in addition to to make coaching quicker and extra secure the beneath ideas have been launched:
-
Substitute any pooling layers with strided convolutions in D. This may be justified as a result of pooling is a hard and fast operation. In distinction, strided convolution can be considered as studying the pooling operation, which will increase the mannequin’s expressiveness skill. The drawback is that it additionally will increase the variety of trainable parameters.
-
Use transpose convolutions in G. As a result of sampled noise is a 1D vector, it’s normally projected and reshaped to a small 2D grid (i.e. 4×4), with an infinite quantity of characteristic maps. That’s why G makes use of transpose convolutions to extend spatial dimensions (normally doubles them) and reduces the variety of characteristic maps.
-
Use batch normalization in each G and D. Batch normalization stabilizes coaching and allows coaching with larger studying charge, primarily based on the statistics of every batch within the layer.
-
Take away absolutely linked hidden layers for deeper architectures to scale back the variety of coaching parameters and coaching time.
-
Use ReLU activation in G for all layers aside from the output, which produces values within the picture vary [-1,1]
-
Use LeakyReLU activation within the discriminator for all layers. Each activation features are nonlinear and allow the mannequin to study extra advanced representations.
-
D has fewer characteristic maps than the in contrast technique (Ok-means). On the whole, for G and D, it’s not clear which mannequin must be extra advanced, as a result of it’s task-dependent. On this work, G has extra trainable parameters than D. Nevertheless, there isn’t any theoretical justification behind this design alternative.

The unconditional generator of DCGAN
Outcomes and dialogue
Let’s observe the output of a DCGAN mannequin in MNIST dataset, given a easy implementation
 Improved picture high quality with DCGAN
Improved picture high quality with DCGAN
The output digits are extra cripsy and include much less noise, utilizing convolutional modules. If you wish to observe mode collapse in follow you’ll be able to attempt to practice a DCGAN in CIFAR-10, utilizing just one class:
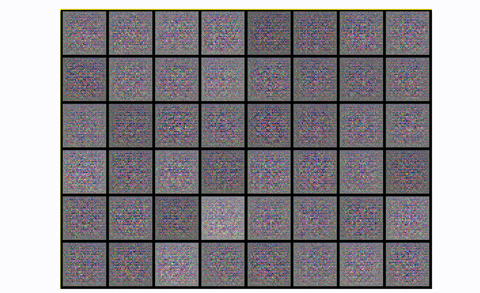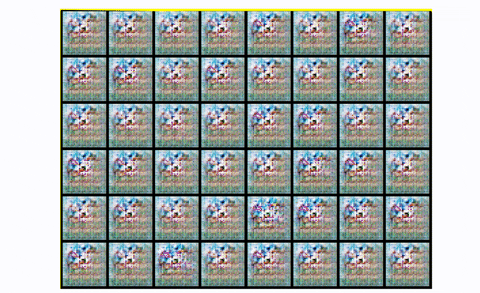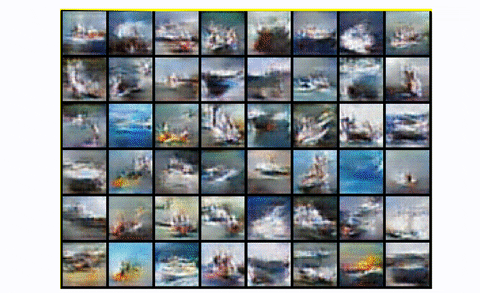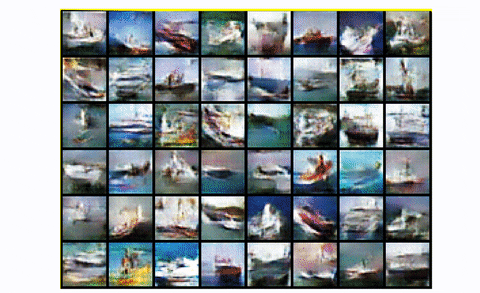 Observing mode collapse in DCGAN in CIFAR10, utilizing one class
Observing mode collapse in DCGAN in CIFAR10, utilizing one class
Principally, you begin with noise. Then you’ve a good illustration with one thing that begins to appear to be the specified pictures. After which growth! The generator actually collapses it’s the repeating sq. patterns. What occurred? Mode collapse!.
To summarize, DCGAN is the usual convolutional baseline that a lot of the subsequent architectures have been primarily based upon. It reveals nice enchancment each by way of visible high quality (much less blurriness) and coaching stability than the usual GAN. Nevertheless, for bigger scales like unconditional picture technology of CIFAR-10 it has a number of area for excellent engineering magic, as we are going to see. Lastly, let’s have a look at the results of coaching DCGAN in the entire CIFAR-10 dataset with all lessons.
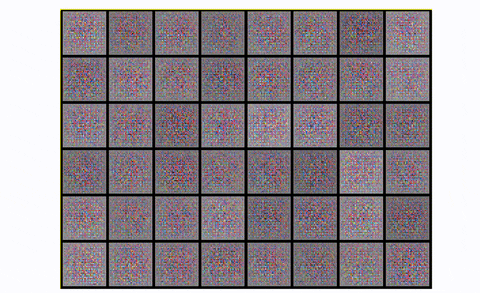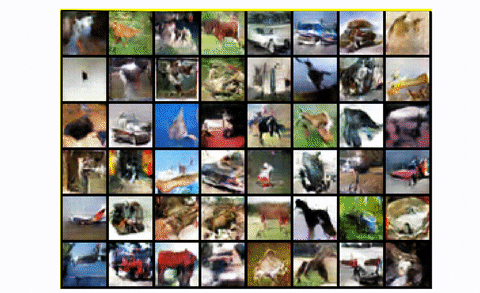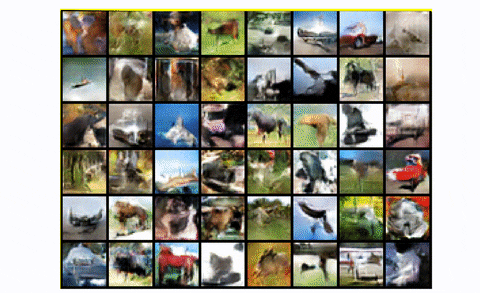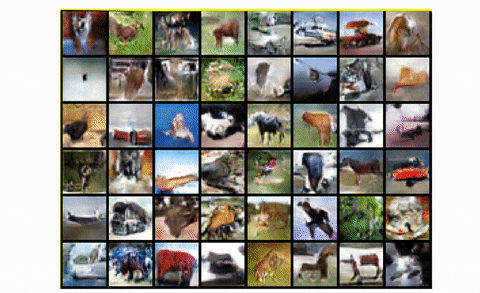 DCGAN in CIFAR10
DCGAN in CIFAR10
Fairly truthful, proper?
Information GAN: Illustration Studying by Info Maximizing Generative Adversarial Nets (2016)
We already talked about conditional variables of cGANs which can be normally class labels or tags. Nevertheless, there are two questions that aren’t answered:
a) how a lot of this data is handed into the technology course of in comparison with noise, and
b) can a very unsupervised situation that lies in a latent area assist us “stroll” within the generator area?
This work addresses these questions by means of disentangled representations and mutual data.
Disentangled representations
Disentangled illustration is an unsupervised studying approach that breaks down (disentangles) every characteristic into narrowly outlined variables and encodes them as separate dimensions. As said within the authentic Information GAN paper, a disentangled illustration will be helpful for pure duties that require data of the vital attributes of the information (face recognition, object recognition). Personally, I like to think about disentangled illustration as a decoded data of a decrease dimensionality of the information. Due to this fact, it’s argued {that a} good generative mannequin will routinely study a disentangled illustration.
The motivation is that the flexibility to synthesize the noticed knowledge has some type of understanding. Principally, we want the mannequin to uncover unbiased and demanding unsupervised representations. That is achieved by introducing just a few unbiased steady/categorical variables. The query is what makes these conditional variables (normally referred to as latent codes) completely different from the present enter noise in a GAN? Mutual data maximization!
Mutual Info in GANs
In a standard GAN, the generator is free to disregard the extra latent conditional variable. This may be achieved by discovering an answer satisfying: P(x|c) = P(x). To deal with the issue of trivial codes, an information-theoretic regularization is proposed. Extra particularly, there must be excessive mutual data between latent codes c and generator distribution G(z, c).
Mutual data (MI) of two random variables (the situation and the output) is a quantitative measure of the mutual dependence between them. Much less actually, it quantifies the “quantity of knowledge” obtained about our conditioned variables by observing the generator’s output. Thus, if I is the quantity of code data given the generator output, then I(c | G(z, c)) must be excessive. MI has an intuitive interpretation: it’s the discount of uncertainty within the generated output when the conditional random variable is noticed.
As a consequence, we wish to P(c|x) to be excessive (small entropy). That implies that given the noticed generated picture x, there’s a excessive chance that we’ll observe the situation. In different phrases, the knowledge within the latent variable c shouldn’t be misplaced within the technology course of. The subsequent questions come up by itself, how can we estimate the conditional distribution P(c|x)? Let’s practice a neural community to mannequin the specified distribution!
Implementing conditional mutual data
As a result of it provides additional complexity so as to add one other community to mannequin this chance, the authors suggest to mannequin it with the present discriminator by including a further layer that outputs this chance. So, D has one other goal to study: maximizing mutual data! This additional goal is the rationale it’s referred to as mutual data regularization within the title (much like weight decay).
Therefore, given Q the mannequin that has the layers of D plus an additional classification layer, one can outline the auxiliary loss L_I(G, Q), that’s added to GAN’s aims. Lastly, we have now no change to GAN’s coaching process with nearly no additional overhead (computationally free additional goal). That’s what makes InfoGan such an exquisite concept!
Outcomes
Various the continual conditional variables, it’s illustrated that we are able to navigate within the excessive dimensional area of the picture with the low-dimensional disentangled illustration. Really, it’s noticed that illustration studying results in significant representations similar to rotation and thickness. The code will be discovered right here.

Unsupervised modeling of rotation and thickness, InfoGAN
“What’s outstanding is that in latent variables, the generator doesn’t merely stretch or rotate the digits however as an alternative modify different particulars like thickness or stroke fashion to ensure the ensuing pictures are pure trying.” ~ InfoGAN
For a hands-on video course we extremely suggest coursera’s brand-new GAN specialization. When you favor a e-book with curated content material begin from the “GANs in Motion” e-book!
This can be a nice experimental work that summarizes coaching tips that you need to use by yourself drawback to stabilize coaching in GANs. Since GAN coaching consists of discovering a two-player Nash equilibrium gradient descent might fail to converge for a lot of duties (video games). Principally Nash equilibrium is a degree that not one of the gamers can enhance by altering its weights. The principle cause is that the associated fee operate is normally non-convex and the parameters are steady. Lastly, the parameter area is extraordinarily high-dimensional.
To higher perceive that, suppose that the duty of predicting a picture of decision 128×128 (16384 pixels) is like looking for a path in a posh world of R16384. The high-dimensional path is named a manifold and is mainly the set of generated pictures which can be satisfying our goal. If our goal is to study human faces, then our objective is to discover a actually small subset of the world that represents human faces. Shifting on this path is transferring contained in the vectors options that symbolize faces. I strongly suggest this video by Nvidia. The code of this work will be discovered right here. Now, allow us to bounce proper on then coaching magic!
Characteristic matching
Principally, the generator is skilled to match the anticipated worth of the options on an intermediate layer of the discriminator. The brand new goal requires the generator to generate knowledge that matches the statistics (intermediate representations) of the true knowledge. By coaching the discriminator on this method we ask D to seek out these options which can be most discriminative of actual knowledge versus knowledge generated by the present mannequin. The empirical outcomes so far point out that characteristic matching is certainly efficient in conditions the place common GAN turns into unstable. To measure the space the L2 norm is adopted.
Minibatch discrimination
Concept: Minibatch discrimination permits us to generate visually interesting samples in a short time.
Motivation: As a result of the discriminator processes every instance independently, there may be no coordination between its gradients, and thus no mechanism to inform the outputs of the generator to turn out to be extra dissimilar to one another.

How mini-batch discrimination works.
Answer: permit the discriminator to have a look at a number of knowledge examples together, and carry out what we name minibatch discrimination. As proven within the above determine, the intermediate characteristic vectors are multiplied by a 3D tensor to get a sequence of matrices denoted by M1..Mn. Based mostly on the matrices, the remaining objective is to quantify a measure of pairwise similarity for every knowledge pair. Intuitively, each pattern now could have further data o(xi) that expresses the similarity in comparison with the remaining knowledge samples.
In reality, they concatenate the output similarity o(xi) of the minibatch layer with the intermediate options f(xi) that have been its enter. Then, the result’s fed into the subsequent layer of the discriminator. The duty of the discriminator is thus successfully nonetheless to categorise single examples as actual knowledge or generated knowledge, however it’s now in a position to make use of the opposite examples within the minibatch as facet data. Nevertheless, the computational complexity of this technique is large, as a result of it requires the pairwise similarity between all samples.
Historic weight averaging
The historic common of the parameters will be up to date in a web-based vogue so this studying rule scales nicely to very long time collection. It may be helpful for low-dimensional issues the place gradient descent might fail. If in case you have ever appeared how momentum works, it really works by the identical basis, solely that it accounts solely the earlier gradient. Historic weight averaging is roughly the identical however for a number of timesteps prior to now.
One-sided label smoothing and Digital batch normalization
Label smoothing solely within the optimistic labels (real-data samples) to α (as an alternative of 0). Not an excessive amount of to say right here. Versus customary batch normalization, in Digital batch normalization, every instance x is normalized primarily based on the statistics collected on a reference batch of examples. The motivation is that batch normalization causes the output of a neural community for an enter instance x to be extremely dependent on the opposite inputs of the identical minibatch. To deal with this, a reference batch of examples is chosen as soon as and it’s stored mounted throughout coaching. Nevertheless, the reference batch is normalized utilizing solely its personal statistics, making it computationally costly.
Inception rating: evaluating picture high quality
As an alternative of inspecting the visible high quality one after the other, a brand new quantitative technique to judge the mannequin is proposed. This may merely be described as a two-step strategy: first, infer the label (conditional chance) of the generated picture utilizing a pre-trained classifier (InceptionNet). Then, measure the KL divergence of the classifier in comparison with unconditional chance. To this finish, we do not want volunteers to judge our fashions and we are able to quantify the mannequin’s rating.
Semi-supervised studying
It’s doable to do semi-supervised studying with any customary classifier by merely including samples from the GAN generator G to our knowledge set, labeling them with a brand new “generated” class, or with out additional class on condition that the pre-trained classifier acknowledged the label (conditional chance) with low entropy (excessive chance i.e human 97/100).
Outcomes and dialogue

Taken from the unique publication
Based mostly on the proposed strategies GANs are in a position for the primary time to study distinguishable options. The illustrated animal options embody eyes and noses. However, these options are usually not accurately mixed to kind an animal with a sensible anatomical construction. Nonetheless, it’s a nice step in direction of the evolution of GANs. To summarize, the outcomes of this foundational work are:
Based mostly on the thought of characteristic matching, it’s doable to supply international statistics acknowledged by people. This occurs as a result of the human visible system is strongly attuned to picture statistics that may assist infer the category a picture represents, whereas it’s presumably much less delicate to native statistics which can be much less vital for the interpretation of the picture. Nevertheless, we are going to see in a subsequent article that higher fashions attempt to study each of them with completely different strategies.
Moreover, by having the discriminator D classify the item proven within the picture, the authors attempt to bias D, in order to develop an inside illustration. The latter places emphasis on the identical options that people emphasize. This impact will be understood as a technique for switch studying, and will doubtlessly be utilized way more broadly.
Conclusion
On this article, we construct upon the concepts of generative studying. We introduce ideas as adversarial studying and GAN coaching schemes. Then, we mentioned mode collapse, conditional technology and disentangled representations primarily based on mutual data. Based mostly on the noticed coaching issues, we launched the essential tips to coach GANs. Lastly, we noticed some outcomes whereas coaching the community and virtually noticed mode collapse. For an superior lately launched repo with a number of GANs for heavy experimentation go to this repo.
If you would like a model new superior course on GANs, we extremely suggest the Coursera specialization. If you wish to construct up your background on autoencoders additionally we suggest the next Udemy course.
By now, you begin to notice that what we declare to be simply the primary half, is what the vast majority of tutorials declare to be an entire GAN information. Nevertheless, there may be way more attention-grabbing stuff that I humbly ask you to contemplate checking the remainder of the collection. One GAN-article per day is extra that sufficient!
Within the subsequent article, we are going to see extra superior architectures and coaching tips that led to larger decision pictures and 3D object technology.
Lastly, if you wish to be notified when our free GAN e-book will likely be revealed, subscribe to our e-newsletter to have it delivered to your inbox instantly!
Keep tuned for extra!
Cited as:
@article{adaloglou2020gans,
title = "GANs in pc imaginative and prescient",
writer = "Adaloglou, Nikolas and Karagiannakos, Sergios ",
journal = "https://theaisummer.com/",
12 months = "2020",
url = "https://theaisummer.com/gan-computer-vision/"
}
References
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural data processing programs (pp. 2672-2680).
- Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised illustration studying with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434. - Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). Infogan: Interpretable illustration studying by data maximizing generative adversarial nets. In Advances in neural data processing programs (pp. 2172-2180).
- Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved strategies for coaching gans. In Advances in neural data processing programs (pp. 2234-2242).

* Disclosure: Please notice that a few of the hyperlinks above is perhaps affiliate hyperlinks, and at no further value to you, we are going to earn a fee should you resolve to make a purchase order after clicking by means of.