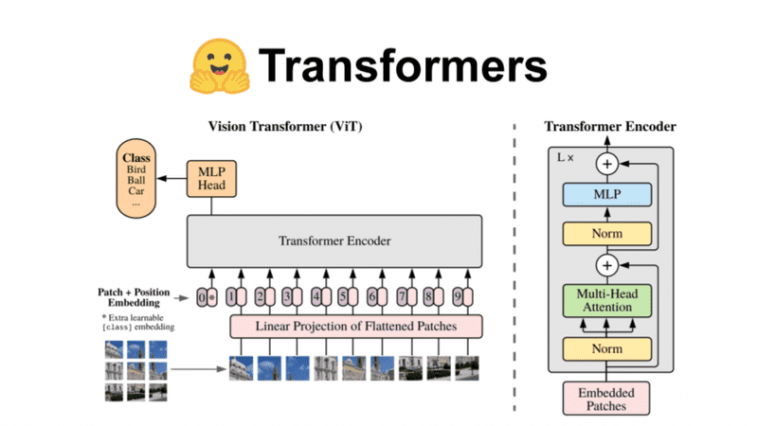
This text serves as an all-in tutorial of the Hugging Face ecosystem. We are going to discover the completely different libraries developed by the Hugging Face workforce equivalent to transformers and datasets. We are going to see how they can be utilized to develop and practice transformers with minimal boilerplate code. To higher elaborate the essential ideas, we’ll showcase the complete pipeline of constructing and coaching a Imaginative and prescient Transformer (ViT).
I assume that you just already are acquainted with the structure so we gained’t analyze a lot about it. A number of issues to recollect are:
-
In ViT, we signify a picture as a sequence of patches .
-
The structure resembles the unique Transformer from the well-known “Consideration is all you want” paper.
-
The mannequin is educated utilizing a labeled dataset following a fully-supervised paradigm.
-
It’s normally fine-tuned on the downstream dataset for picture classification.
In case you are fascinated about a holistic view of the ViT structure, go to one in every of our earlier articles on the subject: How the Imaginative and prescient Transformer (ViT) works in 10 minutes: a picture is value 16×16 phrases.
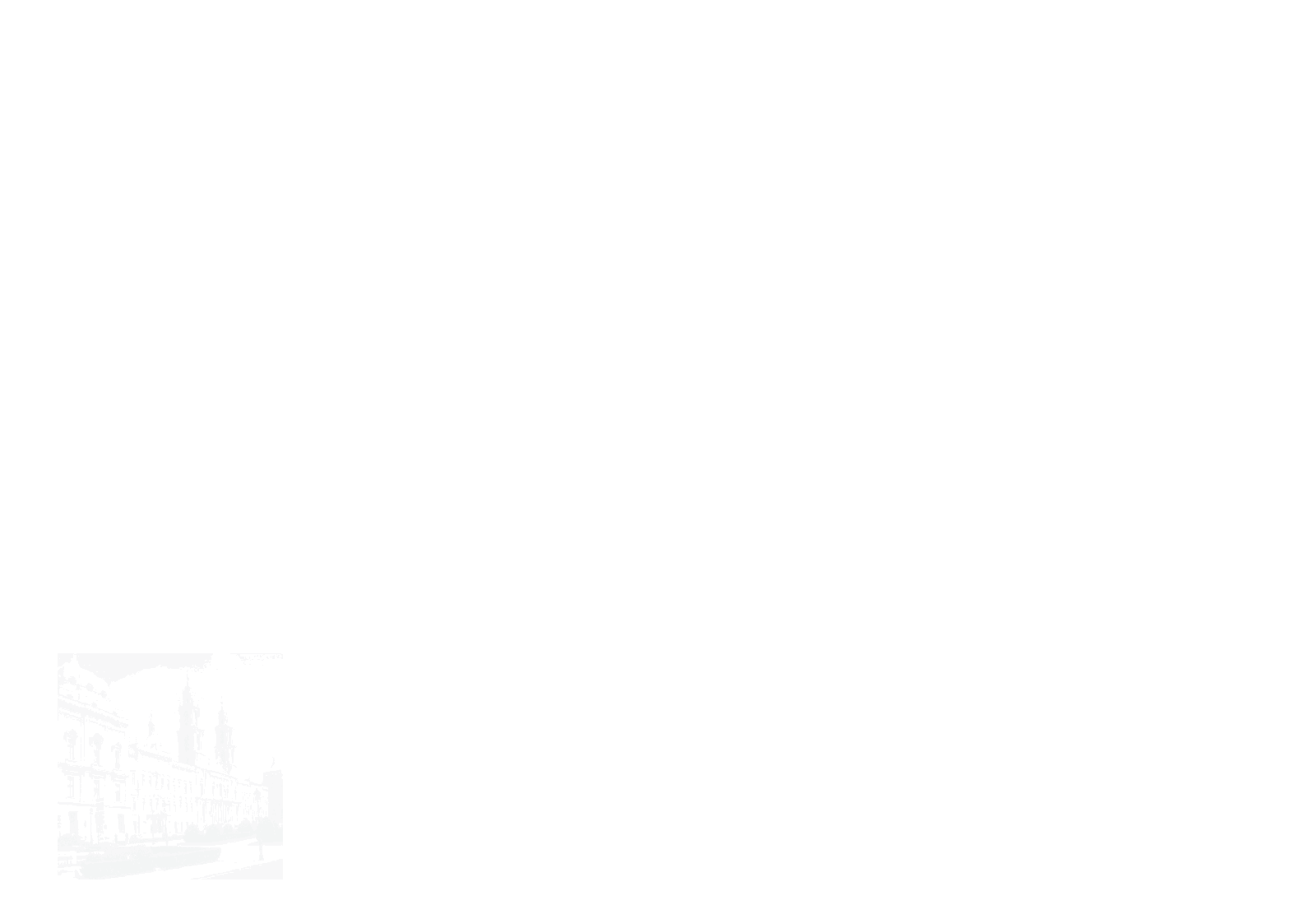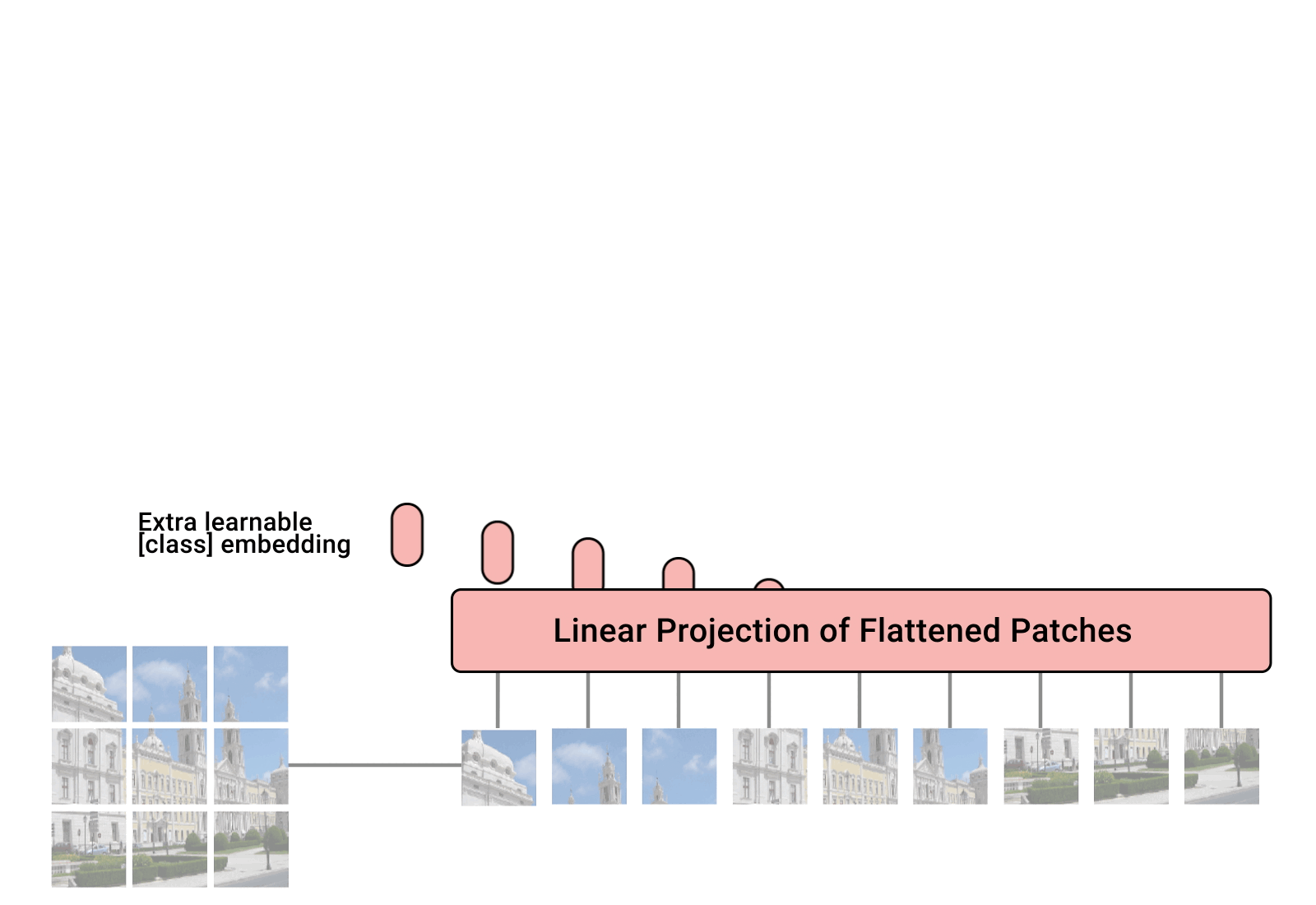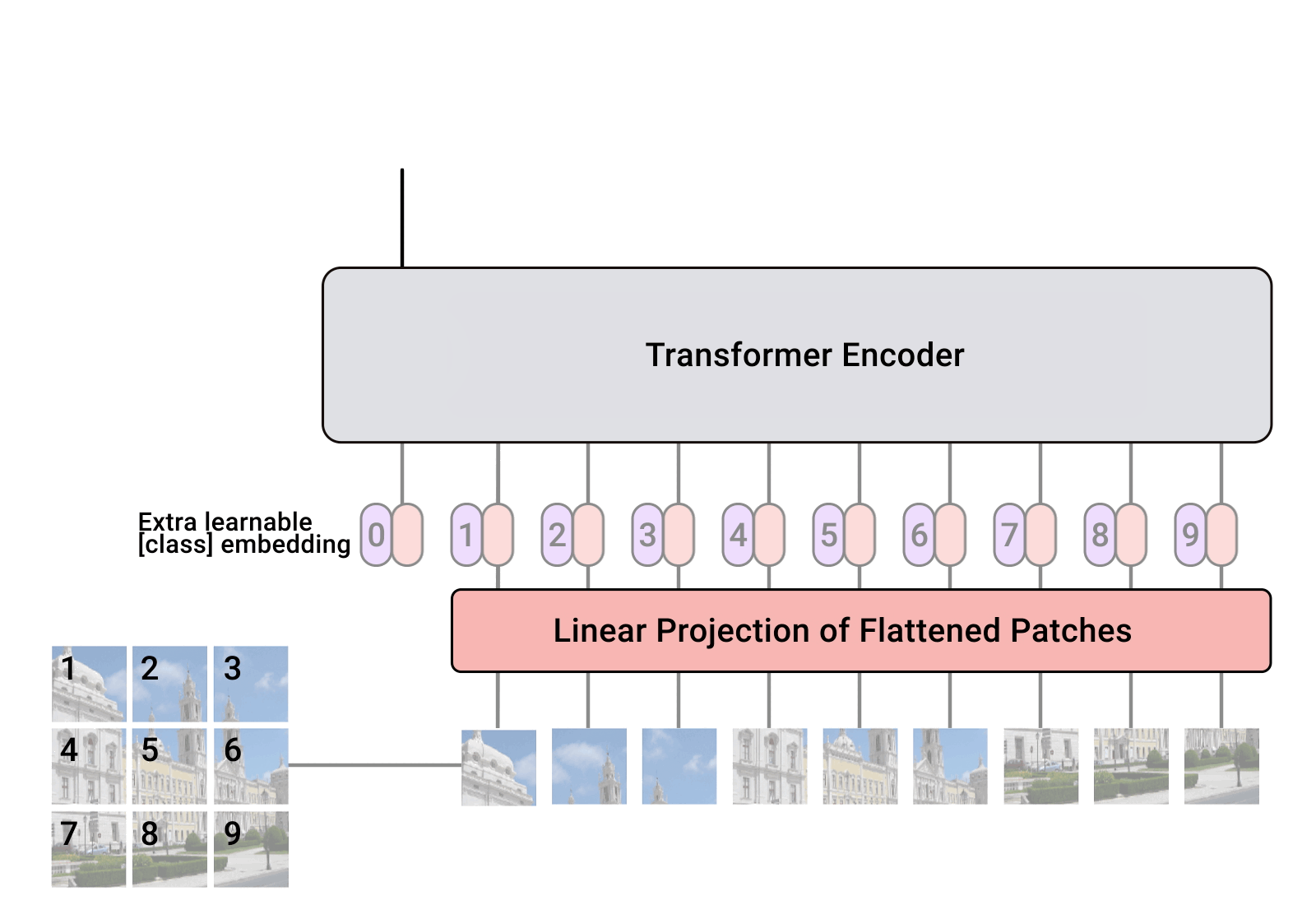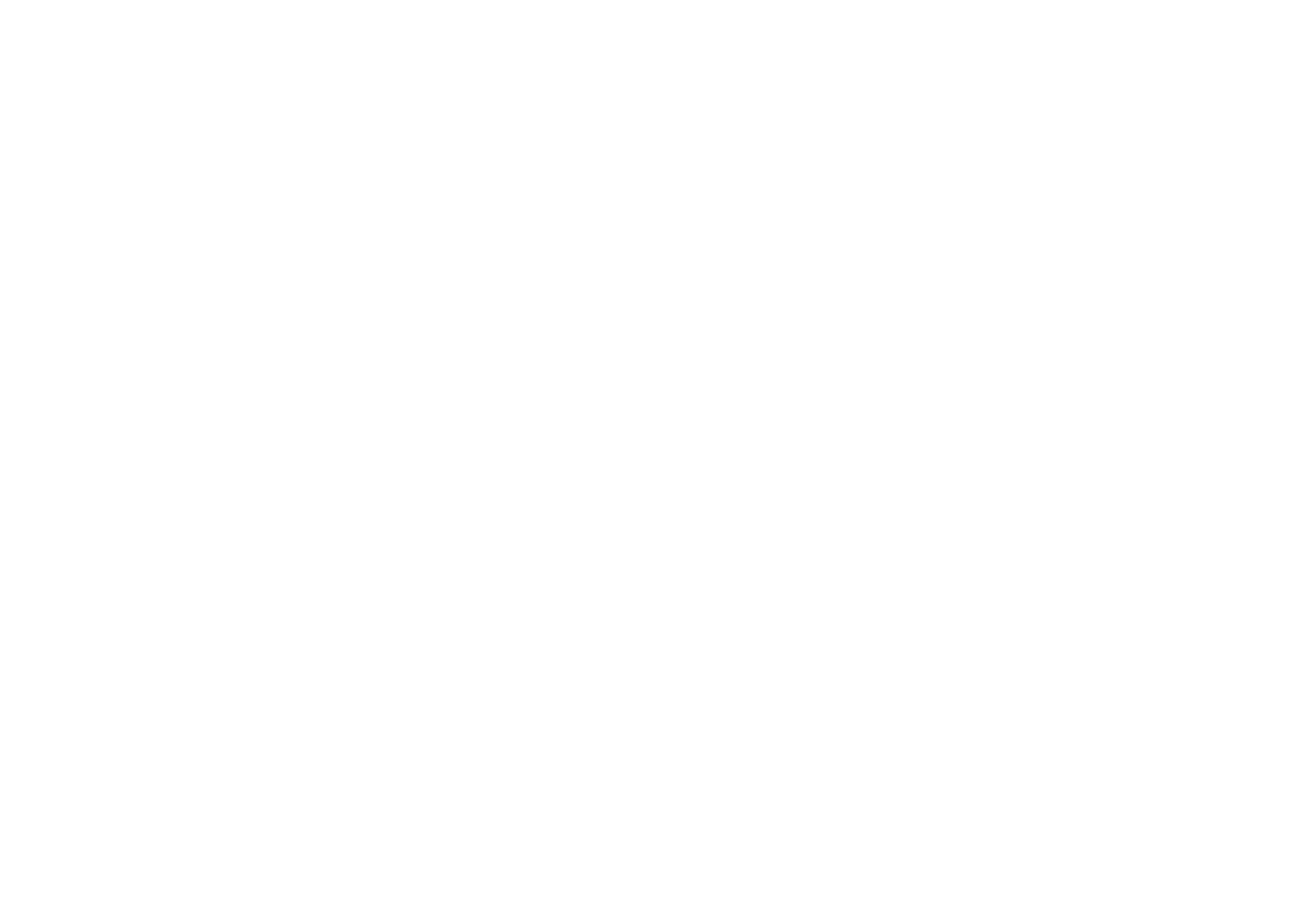 Supply: Google AI weblog
Supply: Google AI weblog
Again to Hugging face which is the principle goal of the article. We are going to attempt to current the elemental rules of the libraries protecting the complete ML pipeline: from information loading to coaching and analysis.
Shall we start?
Datasets
The datasets library by Hugging Face is a set of ready-to-use datasets and analysis metrics for NLP. In the meanwhile of scripting this, the datasets hub counts over 900 completely different datasets. Let’s see how we will use it in our instance.
To load a dataset, we have to import the load_dataset perform and cargo the specified dataset like under:
from datasets import load_dataset
train_ds, test_ds = load_dataset('cifar10', break up=['train[:5000]', 'take a look at[:2000]'])
Discover that right here we load solely a portion of the CIFAR10 dataset. Utilizing load_dataset, we will obtain datasets from the Hugging Face Hub, learn from a neighborhood file, or load from in-memory information. We will additionally configure it to make use of a customized script containing the loading performance.
Sometimes, the dataset will probably be returned as a datasets.Dataset object which is nothing greater than a desk with rows and columns. Querying a row will return a python dictionary with keys akin to the column names and values to the worth on this explicit row-column cell. In different phrases, every row corresponds to a data-point and every column to a characteristic. We will get the complete construction of the dataset utilizing datasets.options.
A Dataset object is behaving like a Python listing so we will question as we’d usually do with Numpy or Pandas:
The whole lot is a Python object however that doesn’t imply that it will possibly’t be transformed into NumPy, pandas, PyTorch or TensorFlow. This may be very simply achieved utilizing datasets.Dataset.set_format(), the place the format is one in every of 'numpy', 'pandas', 'torch', 'tensorflow'.
No must say that there’s additionally help for all sorts of operations. To call just a few: type, shuffle, filter, train_test_split, shard, forged, flatten and map . map is , after all, the principle perform to carry out transformations and as you’d anticipate is parallelizable.
In our instance, we first want to separate the coaching information right into a coaching and a validation dataset:
splits = train_ds.train_test_split(test_size=0.1)
train_ds = splits['train']
val_ds = splits['test']
Metrics
The datasets library additionally gives a large listing of metrics that can be utilized when coaching fashions. The principle object here’s a datasets.Metric and may be utilized into two methods:
-
We will both load an current metric from the Hub utilizing
datasets.load_metric(‘metric_name’) -
Or we will outline a customized metric in a separate script and cargo it utilizing: `load_metric(‘PATH/TO/MY/METRIC/SCRIPT’)“`
from datasets import load_metric
metric = load_metric("accuracy")
Transformers
Transformers is the principle library by Hugging Face. It gives intuitive and extremely abstracted functionalities to construct, practice and fine-tune transformers. It comes with nearly 10000 pretrained fashions that may be discovered on the Hub. These fashions may be in-built Tensorflow, Pytorch or JAX (a really latest addition) and anybody can add his personal mannequin.
Alongside with our instance code, we’ll dive a bit deeper into the principle lessons and options of the transformers library.
Pipelines
The pipeline abstraction is an intuitive and simple approach to make use of a mannequin for inference. They summary a lot of the code from the library and supply a devoted API for a wide range of duties. Examples embrace: AutomaticSpeechRecognitionPipeline, QuestionAnsweringPipeline , TranslationPipeline and extra.
The pipeline object lets us additionally outline the pretrained mannequin in addition to the tokenizer, the characteristic extractor, the underlying framework and extra. Tokenizer and have extractors? What are these? Maintain that thought for the following part.
In our case, we will use the transformers.ImageClassificationPipeline as under:
from transformers import ViTForImageClassification
mannequin = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
mannequin.eval()
The mannequin can now be used for inference. All we have now to do is feed a picture and we’re good to go.
Nevertheless, in lots of instances, we additionally want to coach or fantastic tune a mannequin. Maybe we additionally need higher management on the complete pipeline. Due to this fact, we would must develop the code ourselves. For academic functions, that is what we’ll do right here.
Making ready the dataset
Step one to any ML lifecycle is to rework the dataset. In our case, we have to preprocess the CIFAR10 photographs in order that we will feed them to our mannequin. Hugging Face has two fundamental lessons for information processing. Tokenizers and have extractors.
Tokenizers
In most NLP duties, a tokenizer is our go-to resolution. A tokenizer is mapping the textual content into tokens after which into numerical inputs that may be fed into the mannequin. Every mannequin comes with its personal tokenizer that’s primarily based on the PreTrainedTokenizer class.
Since we’re coping with photographs, we is not going to use a Tokenizer right here. We are going to cowl them extra extensively in a future tutorial.
Nevertheless, we’ll make use of one other class referred to as characteristic extractors. A characteristic extractor is normally answerable for getting ready enter options for fashions that don’t fall into the usual NLP fashions. They’re in command of issues equivalent to processing audio information and manipulating photographs. Most imaginative and prescient fashions include a complementary characteristic extractor.
from transformers import ViTFeatureExtractor
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
This characteristic extractor will resize each picture to the decision that the mannequin expects and normalize the channels. You will discover the complete processing performance right here.
Now we will outline the complete processing performance as depicted under:
def preprocess_images(examples):
photographs = examples['img']
photographs = [np.array(image, dtype=np.uint8) for image in images]
photographs = [np.moveaxis(image, source=-1, destination=0) for image in images]
inputs = feature_extractor(photographs=photographs)
examples['pixel_values'] = inputs['pixel_values']
return examples
from datasets import Options, ClassLabel, Array3D
options = Options({
'label': ClassLabel(names=['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']),
'img': Array3D(dtype="int64", form=(3,32,32)),
'pixel_values': Array3D(dtype="float32", form=(3, 224, 224)),
})
preprocessed_train_ds = train_ds.map(preprocess_images, batched=True, options=options)
preprocessed_val_ds = val_ds.map(preprocess_images, batched=True, options=options)
preprocessed_test_ds = test_ds.map(preprocess_images, batched=True, options=options)
A number of issues to notice right here:
-
We have to outline the
Optionsourselves to make it possible for the enter will probably be within the right format.pixel_valuesis the principle enter a ViT mannequin expects as one can examine within the ahead cross of the mannequin. -
We use the
map()perform to use the transformations. -
ClassLabelandArray3Dare sorts of options from thedatasetslibrary.
Knowledge collator
One other essential step of the preprocessing pipeline is batching. We sometimes wish to kind batches from our dataset when coaching our mannequin. Knowledge collators are objects that assist us do precisely that.
In our case, the default information collator supplied from the library needs to be sufficient.
from transformers import default_data_collator
data_collator = default_data_collator
We are going to cross the information collator as an argument to the coaching loop. Extra on that shortly.
Defining the mannequin
Pretrained transformer fashions may be loaded utilizing the perform from_pretrained(‘model_name’). This can instantiate the chosen mannequin and assign the trainable parameters. The mannequin is by default in analysis mode mannequin.eval(), so we have to execute mannequin.practice() with a purpose to practice it.
from transformers import ViTForImageClassification
mannequin = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224-in21k')
mannequin.practice()
Pretrained fashions can be utilized as a base for improved fashions. An instance may be discovered under:
from transformers import ViTModel
class ViTForImageClassification2(nn.Module):
def __init__(self, num_labels=10):
tremendous(ViTForImageClassification2, self).__init__()
self.vit = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
self.classifier = nn.Linear(self.vit.config.hidden_size, num_labels)
self.num_labels = num_labels
def ahead(self, pixel_values, labels):
outputs = self.vit(pixel_values=pixel_values)
logits = self.classifier(output)
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
Right here we prolong the VitModel by including a linear layer on the finish, hoping to amass a greater illustration of the enter picture. As you’ll be able to think about, we’re in a position to modify the community as we wish.
Modeling outputs
Did you discover the SequenceClassifierOutput on the finish of the mannequin?
The transformers library forces all of the fashions to supply outputs that inherit the file_utils.ModelOutput class. The ModelOutput is a knowledge construction that has all the data returned by the mannequin. There are lots of completely different subclasses relying on the duty at hand.
Sometimes a ModelOutput accommodates the output of the mannequin and optionally the hidden states. In lots of fashions, the eye weights are additionally supplied. Right here we use the SequenceClassifierOutput which is the principle output for classification fashions.
Coaching the mannequin
Due to the shortage of a standardized training-loop by Pytorch, Hugging Face gives its personal coaching class. Coach is very optimized for transformers and gives an API for each regular and distributed coaching. Coach lets us use our personal optimizers, losses, studying price schedulers, and many others.
We will outline our coaching loop as under:
coach = Coach(
mannequin,
args,
train_dataset = preprocessed_train_ds,
eval_dataset = preprocessed_val_ds,
data_collator = data_collator,
compute_metrics = compute_metrics,
)
Discover that we have to cross the mannequin, the coaching dataset, the validation datasets, the information collator and some different important issues.
compute_metrics is used to calculate the metrics throughout analysis and is a customized perform. An instance could be one thing like this:
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return metric.compute(predictions=predictions, references=labels)
Right here we merely take the mannequin’s output, discover the utmost worth, and compute the metrics with respect to the corresponding label.
Coaching arguments
Coaching arguments are a set of arguments associated to the coaching loop which can be handed into the Coach occasion. These can embrace issues equivalent to: the trail folder the place outputs will probably be written, an analysis technique, the batch dimension per CPU/GPU core, the training price, the variety of epochs and something associated to coaching.
Coaching arguments may be initialized as under:
args = TrainingArguments(
"test-cifar-10",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=10,
per_device_eval_batch_size=4,
num_train_epochs=3,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model=metric_name,
logging_dir='logs',
)
coach.practice()
You will discover the entire listing within the official documentation.
Callbacks
Coaching callbacks couldn’t after all be lacking. The power to examine the coaching course of is an important a part of any machine studying lifecycle. Coach helps a wide range of callbacks that present performance to :
Aside from the above, additionally they provide integration with third celebration software program equivalent to Weights and Biases, MlFlow, AzureML and Comet.
If for instance we wished to visualise the coaching course of utilizing the weights and biases library, we will use the WandbCallback. We will merely add one other argument to the Coach within the type of:
from transformers import WandbCallback
callbacks = [WandbCallback(...)]
One different factor: Check out the logging_dir='logs'. By saving the coaching logs, we will very simply provoke a tensorboard occasion and observe the coaching progress:
$ tensorboard --logdir logs/
Another is to make use of the TensorBoardCallback supplied by the library.
Evaluating the mannequin
To judge the mannequin on the take a look at set, we will once more use the Coach object. This time we’ll make the most of the predict perform which can return the output of the fashions with the suitable metrics (if obtainable).
outputs = coach.predict(preprocessed_test_ds)
y_pred = outputs.predictions.argmax(1)
The metrics can be found utilizing outputs.metrics and accommodates issues just like the take a look at loss, the take a look at accuracy and the runtime.
Lastly, I take this chance to say just a few further options of the transformers library that I discover very useful.
Logging
Transformers include a centralized logging system that may be utilized very simply. Following the logging module of Python, It may be configured to set the format of the logs, the handler, and the verbosity into one of many 5 completely different ranges: CRITICAL, ERROR, WARNING, INFO, DEBUG.
For instance, one can set the verbosity to the INFO degree utilizing:
transformers.logging.set_verbosity_info()
Debugging
One other helpful characteristic is the power to catch underflow or overflow errors. We will configure the bundle to examine inputs, output or weights, and decide if there are any ìnf or nan amongst them. As quickly as an abnormality is detected, this system will print a report notifying the developer.
This may be achieved by an additional coaching argument within the coach occasion: debug="underflow_overflow"
Be aware that this presently works just for Pytorch.
Auto lessons
Auto lessons are an impressed option to alleviate a few of the ache of discovering the proper mannequin or tokenizer for a particular drawback. What do I imply by that?
Think about that you just wish to load the next pretrained DeiT mannequin from the mannequin hub:
fb/deit-base-distilled-patch16-224.
Sometimes this will probably be achieved by doing:
mannequin= DeiTForImageClassification.from_pretrained( 'fb/deit-base-distilled-patch16-224' )
Utilizing an autoclass, this may be simplified into:
mannequin = AutoModel.from_pretrained('fb/deit-base-distilled-patch16-224')
In that case, we don’t must know the corresponding mannequin sort. The autoclass will routinely retrieve the related mannequin to the suitable weights. Right here it’ll create an occasion of DeiTForImageClassification. This will also be prolonged into tokenizers and have extractors:
feature_extractor = AutoFeatureExtractor.from_pretrained( 'fb/deit-base-distilled-patch16-224' )
That concludes our tutorial on Imaginative and prescient Transformers and Hugging Face. By the way in which, you will discover the complete code in our Github repository.
For a extra full introduction to Hugging Face, try the Pure Language Processing with Transformers: Constructing Language Functions with Hugging Face e book by 3 HF engineers
Acknowledgements
An enormous shout out to Niels Rogge and his wonderful tutorials on Transformers. The code introduced on this article is closely impressed by it and modified to go well with our wants. He additionally deserves many thanks for being the principle contributor so as to add the Imaginative and prescient Transformer (ViT) and Knowledge-efficient Picture Transformers (DeiT) to the Hugging Face library.
Conclusion
The Hugging Face workforce has completed a terrific job in enhancing AI analysis. We’re tremendous glad that this endeavor is slowly increasing into imaginative and prescient as properly. Trying ahead to seeing extra fashions and datasets of their hub.
Tell us for those who discover the article helpful on our Discord server. See you subsequent week.

* Disclosure: Please notice that a few of the hyperlinks above could be affiliate hyperlinks, and at no extra price to you, we’ll earn a fee for those who resolve to make a purchase order after clicking by means of.

