Up to now we’ve seen a number of pc imaginative and prescient duties reminiscent of object technology, video synthesis, unpaired picture to picture translation. Now, we’ve reached publications of 2019 in our journey to summarize all essentially the most influential works from the start of GANs. We deal with instinct and design decisions, quite than boringly reported numbers. In the long run, what’s the worth of a reported quantity in a visible technology job, if the outcomes are usually not interesting?
On this part, we selected two distinctive publications: picture synthesis based mostly on a segmentation map and unconditional technology based mostly on a single reference picture. We current a number of views that one has to take into consideration when designing a GAN. The fashions that we are going to go to on this tutorial have tackled the duties out of the field and from a variety of views.
Allow us to start!
GauGAN (Semantic Picture Synthesis with Spatially-Adaptive Normalization 2019)
We’ve got seen a variety of works that obtain as enter the segmentation map and output a picture. When one thing is nice, the query that all the time is available in my thoughts is: can we do higher?
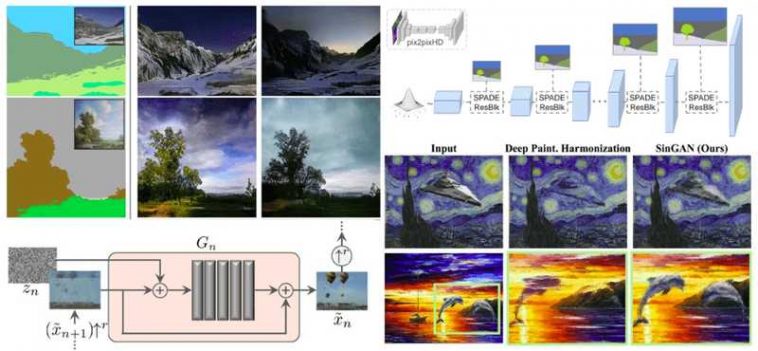
Let’s say that we are able to develop on this concept a bit extra. Suppose that we need to generate a picture given each a segmentation map and a reference picture. This job, outlined as semantic picture synthesis, is of nice significance. We don’t simply generate numerous photos based mostly on the segmentation map, however we additional constrain our mannequin to account for the reference picture that we would like.
This work is the epitome of NVidia in GANs in pc imaginative and prescient. It borrows closely from earlier works of pix2pixHD and StyleGAN. Truly, they borrowed the multi-scale discriminator of pix2pixHD. Let’s have a look on the way it works:

Multi-scale pix2pixHD discriminator overview, picture pyramid borrowed from right here
Primarily based on this, additionally they inspected the generator of StyleGAN. The generator of this mannequin exploits adaptive occasion normalization (AdaIN) to encode the type of the latent house illustration. Mainly it receives noise which is the modeling type. Curiously, they came upon that AdaIN discards semantic content material. Let’s see why:
On this equation, we use the statistics of the function map to normalize its values. Because of this all of the options which are mendacity in a grid construction are normalized by the identical quantity. Since we need to design a generator for type and semantics disentanglement, one strategy to encode the semantics is within the modulation of the in-layer normalizations. Let’s see how we are able to design this by way of SPatially-Adaptive DEnormalization, or simply SPADE!
The SPADE layer
We’ll begin by discarding the earlier layer statistics. So, for every layer within the community, denoted by the index i, with activations and samples, we’ll normalize the channel dimension, as normal. Much like batch normalization, we’ll first normalize with the channel sensible imply and commonplace deviation.
As stated, that is much like step one of the batch norm. Val within the final equation is the normalized worth, which is identical for all of the values within the 2D grid.
Nonetheless, since we don’t need to lose the grid construction we won’t rescale all of the values equally. In contrast to present normalization approaches, the brand new scaled values will likely be 3D tensors (not vectors!). Exactly, given a two-layer convolutional community with two outputs (normally referred to as heads within the literature), we’ve:
Since segmentation maps don’t include steady values, we undertaking them in an embedding house by way of 2 convolutional layers.
Mainly, every location within the 2D grid (y,x) may have its personal scale parameters, totally different for every location based mostly on the enter segmentation map. Therefore, the realized new scaling (modulation) parameters naturally encode details about the label format, supplied by the segmentation map. An superior illustration is introduced, based mostly on the unique work:

The SPADE layer block. The picture is taken from the unique work
So, let’s make a constructing block with this spatially adaptive module! For the reason that earlier statistics are discarded from step one, we are able to embrace a number of such layers that encode totally different components of the specified format. Be aware that, there is no such thing as a want to incorporate the segmentation map within the enter of the generator!
The SPADE Res-block
Following the structure of the additive skip connections of the resnet block, the community can converge sooner and normally in a greater native minimal. It consists of two SPADE layers within the place of the normalization layer. Be aware that in-layer normalizations are all the time utilized earlier than the activation features. That is completed with a view to first scale the vary of the convolutional layers round zero and then clip the values.

The SPADE ResNet block taken from the unique work
Let’s examine the generator and its primary variations between the pix2pixHD generator.
The SPADE-based Generator
For the reason that segmentation map info is encoded within the SPADE constructing blocks, the generator doesn’t have to have an encoder-part. This considerably lowered the variety of trainable parameters.
With a view to match every layer of the generator that operates in a unique spatial dimension, the segmentation map is downsampled. Spade Res-Web block is mixed with Upsampling layers. To summarize, the segmentation masks within the SPADE-based Generator is fed via spatially adaptive modulation with out additional normalization. Solely activations from the earlier convolutional layers are normalized. This method in some way combines some great benefits of normalization with out shedding semantic info. They introduce the notion of spatially various in-layer normalization, which is a novel and vital lengthy term-contribution within the discipline. For the file, segmentation maps had been inferred utilizing a skilled DeepLab Model 2 mannequin by Chen et.al 2017. All of the above will be illustrated under:

The proposed generator, semantic segmentation is injected within the SPADE Res blocks. The picture is taken the unique work
In the meantime, for the reason that generator can take a random vector as enter, it allows a pure manner for picture synthesis, based mostly on a reference picture. That is normally referred to as multi-modal picture synthesis. Merely, we mannequin the latent house to be a illustration of the reference photos. Extra particularly, one can add a picture encoder that embeds the actual picture in a random vector. That is then fed to the generator. The encoder coupled with the generator kind an summary Variational Autoencoder VAE (Kigma et al 2013). The two inputs, particularly the actual picture and segmentation map are encoded in a unique method. The encoder tries to seize the type of the picture, whereas G combines the encoded type and the segmentation masks info by way of the SPADEs to generate a brand new visually interesting picture.
Outcomes and dialogue
In my humble opinion, it’s actually essential that the authors utilized the baseline pix2pixHD with all the opposite developments of the sector that came upon that labored higher, aside from the SPADE generator. Therefore, they introduce a baseline referred to as pix2pixHD++. That is of essential significance as it could actually instantly present the effectiveness of the proposed layer. Curiously, the decoder SPADE-based G works higher than the prolonged baseline pix2pixHD++, with a smaller variety of parameters.

Comparability with different top-performing strategies. The pictures are borrowed from the unique work
Moreover, they included an enormous ablation examine that enforces the effectiveness of the strategy. The SPADE generator is the primary semantic picture synthesis mannequin. It produces numerous photorealistic outputs for a number of scenes together with indoor, out of doors, and panorama scenes. There’s additionally an internet demo which you could see with your individual eyes. It’s price a attempt, belief me. Beneath there’s a comparability with the actual picture of the segmentation map. As loopy as it could sound, these photographs are generated by Gau-GAN!

Comparability with the unique pure photos. Semantic Picture Synthesis in motion, borrowed from the unique work
Lastly, now that you simply understood the magic behind GauGAN, you possibly can benefit from the official video. You can even go to the official undertaking web page for extra outcomes.
SinGAN (Studying a Generative Mannequin from a Single Pure Picture 2019)
Each paper that we mentioned thus far has a one thing distinctive in some side. This paper was voted as the most effective paper within the well-known ICCV 2019 pc imaginative and prescient convention. We noticed that earlier works had been skilled in enormous datasets with 1000’s or tens of millions of photos. In opposition to our frequent instinct, the authors confirmed that the inner statistics of patches inside a single pure picture might carry sufficient info for coaching a GAN.
Design decisions
To take action, they method the only picture as a pyramid, taking a set of downsampled photos, and exploring every scale from coarse to tremendous. With a view to course of totally different enter photos they designed a absolutely convolutional set of GANs. Every explicit community goals to seize the distribution at a unique scale.
That is achieved as a result of a 2D convolutional layer with kernel dimension Okay x Okay solely requires the enter dimension to be bigger than Okay. This system can also be used to coach sooner fashions with smaller inputs patches after which at check time to course of greater resolutions. This isn’t potential in case you have absolutely related layers in your structure since it’s good to predefine the enter dimension.
Furthermore they used the concept of patch-based discriminator from pix2pix. Ideally, the proposed hierarchy of patch-based discriminators, whereas every stage captures the statistics of a unique scale. Much like the generator of progressive rising GANs, they begin from coaching the small scales first, with the distinction that when one scale is skilled they freeze the weights. Moreover they used the gradient penalty Wasserstein GAN, to stabilize the coaching course of.
Let’s see what totally different scales, from coarse to fine-grained particulars appear to be:

Visualizing the totally different output scales. Picture is taken from the unique work
Extra into the structure of SinGAN
The technology of a picture pattern begins on the coarsest scale and sequentially passes via all turbines as much as the best scale. The typical workflow of a single scale works like this: 5 conv. blocks adopted by batch normalization and a ReLU activation course of the upsampled picture. Earlier than the hallucinated picture is fed within the community, noise is added. The spatial dimension is saved all through the block, with padding of 1 and kernel 3 by 3. Subsequently, a brief additive skip-connection will be added, fusing the upsampled picture to the output of the block. This idea considerably helps the mannequin to converge sooner, as we’ve already seen in a variety of approaches. All of the above will be illustrated under:

Constructing block of the generator of 1 scale of SinGAN. Picture is taken from the unique work
Importantly, following different profitable works (BigGAN, StyleGAN), noise is injected at each scale. The reason being that we do not need the generator to memorize the earlier scale, because it’s coaching is stopped. In the identical course, the totally different GANs have small receptive fields and restricted studying capability. Intuitively, we do not need the patches to memorize the enter, since we solely practice with a single picture. Restricted capability refers back to the small variety of parameters.
As a reference, the efficient receptive discipline on the beginning stage is roughly 50% of the picture’s top. Thus, it could actually generate the overall format of the picture (international construction). The pre-described block has a receptive discipline of 11×11, so normally enter photos begin on the scale of 25 pixels.
Reconstruction loss
Curiously, they selected to design the mannequin in a manner that whenever you select zero as enter noise and a set noise for the final layer (z_fixed) the community ought to be skilled to reconstruct the unique picture.
If we regard the actual picture because the zero level of the distribution the reconstruction loss is a measure of normal deviation. Subsequently, the reconstructed picture determines the usual deviation of the noise for every scale.
Outcomes and dialogue
Inspecting the outputs of the mannequin, we observe that the generated photos are practical, whereas they protect the unique picture content material. For the reason that mannequin has a restricted receptive discipline in every patch (smaller than the whole picture), it’s potential to generate new combos of patches that didn’t exist within the enter picture. Beneath you possibly can see how the mannequin encounters the construction of externally injected fashions. We notice that SinGAN preserves the construction of the pasted object, whereas it adjusts its look and texture.

SinGAN outcomes on picture harmonization. Picture is taken from the unique work
Primarily based on the lots outcomes of this work, it’s straightforward to deduce that the SinGAN mannequin can generate practical random picture samples. Surprisingly, even with new constructions and object modulations. Nonetheless, it learns to protect the picture/patch distribution.
For the file, the authors have additionally explored SinGAN for different picture manipulation duties. Given a skilled mannequin, their thought was to make the most of the truth that SinGAN learns the patch distribution of the coaching picture. Therefore, manipulation will be achieved by injecting a picture into the technology pyramid. Intuitively, the mannequin will try to match its patch distribution to that of the coaching picture. Functions embrace picture super-resolution, paint-to-image, harmonization, picture modifying, and even animation from a single picture by “strolling” the latent house!
The official video summarizes the aforementioned contributions of this work that we described on this tutorial.
Lastly, the authors have launched the official code, which will be discovered right here.
Conclusion
We fastidiously inspected the highest performing strategies on picture synthesis from a segmentation map, in addition to studying from only a single picture. For the hungry readers we all the time like to depart a considerate highly-recommended hyperlink. So, now that you simply realized a variety of issues about what designing and coaching a GAN seems to be like, we advocate exploring the open questions on the sector, completely described on this article by Odena et al. 2019. You’ll be able to all the time discover extra papers that could be nearer to your downside right here. Lastly, you need not implement each structure by your self. There’s an superior GAN git repository in Keras and Pytorch that comprises a number of implementations. Be at liberty to examine them out.
That is the final article of the sequence for now. However notice that the GANs in pc imaginative and prescient sequence will stay open to incorporate new papers sooner or later, in addition to present ones we’d have missed. We launched a free e-book that summarizes our conclusions and concatenates all of our articles right into a single useful resource. If you wish to specific your curiosity subscribe to our e-newsletter to obtain it straight into your inbox. For a extra hands-on course go to GANs coursera specialization.
Adaloglou Nikolas and Karagianakos Sergios
Cited as:
@article{adaloglou2020normalization,
title = "In-layer normalization methods for coaching very deep neural networks",
creator = "Adaloglou, Nikolas",
journal = "https://theaisummer.com/",
yr = "2020",
url = "https://theaisummer.com/normalization/"
}
For a hands-on video course we extremely advocate coursera’s brand-new GAN specialization.Nonetheless, should you favor a e book with curated content material in order to start out constructing your individual fancy GANs, begin from the “GANs in Motion” e book!
References
- Park, T., Liu, M. Y., Wang, T. C., & Zhu, J. Y. (2019). Semantic picture synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Convention on Laptop Imaginative and prescient and Sample Recognition (pp. 2337-2346).
- Shaham, T. R., Dekel, T., & Michaeli, T. (2019). Singan: Studying a generative mannequin from a single pure picture. In Proceedings of the IEEE Worldwide Convention on Laptop Imaginative and prescient (pp. 4570-4580).
- Odena, “Open Questions on Generative Adversarial Networks”, Distill, 2019.
- He, Okay., Zhang, X., Ren, S., & Solar, J. (2016). Deep residual studying for picture recognition. In Proceedings of the IEEE convention on pc imaginative and prescient and sample recognition (pp. 770-778).
- Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114.
- Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, Okay., & Yuille, A. L. (2017). Deeplab: Semantic picture segmentation with deep convolutional nets, atrous convolution, and absolutely related crfs. IEEE transactions on sample evaluation and machine intelligence, 40(4), 834-848.

* Disclosure: Please notice that among the hyperlinks above could be affiliate hyperlinks, and at no extra value to you, we’ll earn a fee should you resolve to make a purchase order after clicking via.
