Within the earlier put up, we totally launched and inspected all of the features of the LSTM cell. One could argue that RNN approaches are out of date and there’s no level in finding out them. It’s true {that a} newer class of strategies referred to as Transformers [5] has completely nailed the sector of pure language processing. Nonetheless, deep studying by no means ceases to shock me, RNN’s included. In the future perhaps we see an enormous comeback. Remember the fact that RNN’s are nonetheless the most effective in comparison with Transformers alternative when:
-
The sequence size is simply too lengthy.
-
The duty requires real-time management (robotics) or subsequent timesteps aren’t out there a priori.
-
There may be not an infinite dataset to use the switch studying capabilities of transformers.
-
The pc imaginative and prescient downside is weakly supervised (motion recognition). Sure. RNN together with the Connectionist Temporal Classification (CTC) loss [6] nonetheless works fairly nicely.
Different causes to know extra on RNN embrace hybrid fashions. As an example, I not too long ago got here throughout a mannequin [4] that produces life like real-valued multi-dimensional medical information collection, that mixes recurrent neural networks and GANs. So that you by no means know the place they might come helpful.
In any case, fundamentals are to be mastered. This time, we are going to overview and construct the Gated Recurrent Unit (GRU), as a pure compact variation of LSTM. Lastly, we are going to present a number of comparative insights on which cell to make use of, primarily based on the issue.
Accompanying pocket book code is offered right here.
GRU: simplifying the LSTM cell
Now we have seen how LSTM’s are capable of predict sequential information. The issue that arose when LSTM’s the place initially launched was the excessive variety of parameters. Let’s begin by saying that the motivation for the proposed LSTM variation referred to as GRU is the simplification, by way of the variety of parameters and the carried out operations.
Earlier than we soar within the equations let’s make clear one essential truth: the ideas of LSTM and GRU cells are widespread, by way of modeling long-term sequences. First, we will course of an arbitrary variety of timesteps, Moreover, we try to scrub away redundant info and incorporate a reminiscence part saved within the weights. The reminiscence is launched within the community by the hidden state vector which is exclusive for every enter sequence, every time ranging from a zero factor vector for .
Now, let’s see the marginally completely different math! Once more, we are going to analyze them step-by-step. I’m simply presenting them right here as a reference level.
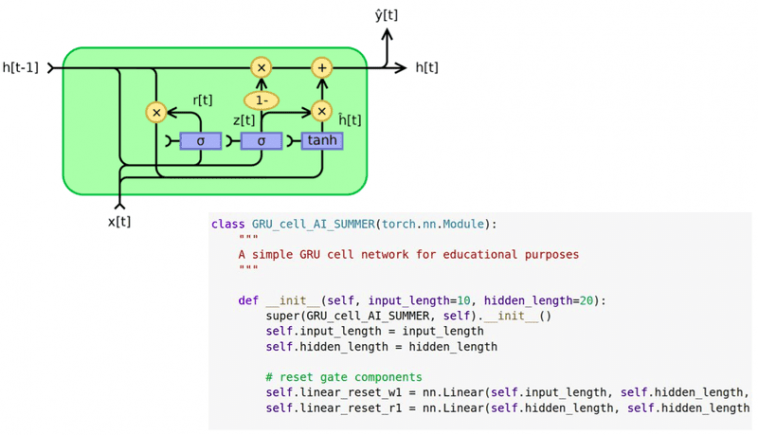
For , the place N is the function size of every timestep, whereas , the place H is the hidden state dimension, the GRU equations are the next:
Equation 1: Reset gate
This gate is pretty just like the neglect gate of the LSTM cell. The ensuing reset vector r represents the knowledge that can decide what can be faraway from the earlier hidden time steps. As within the neglect gate, we apply the neglect operation by way of element-wise multiplication, denoted by the Hadamard product operator. We calculate the reset vector as a linear mixture of the enter vector of the present timestep in addition to the earlier hidden state.
Each operations are calculated with matrix multiplication (nn.Linear in PyTorch). Observe that for the primary timestep the hidden state is normally a vector full of zeros. Because of this there isn’t any details about the previous. Lastly, a non-linear activation is utilized (i.e. sigmoid). Furthermore, through the use of an activation perform (sigmoid) the end result lies within the vary of (0, 1), which accounts for coaching stability.
Equation 2: the replace gate – the shared replace gate vector z
The merging of the enter and output gate of the GRU within the so-called replace gate occurs simply right here. We calculate one other illustration of the enter vector x and the earlier hidden state, however this time with completely different trainable matrices and biases. The vector z will characterize the replace vector.
Equation 3: The just about output part
The vector n consists of two elements; the primary one being a linear layer utilized to the enter, just like the enter gate in an LSTM. The second half consists of the reset vector r and is utilized within the earlier hidden state. Observe that right here the neglect/reset vector is utilized straight within the hidden state, as an alternative of making use of it within the intermediate illustration of cell vector c of an LSTM cell.
Equation 4: the brand new hidden state
To start with, within the depicted equation notice that 1 is mainly a vector of ones. For the reason that values of z lie within the vary (0,1), 1-z additionally belongs in the identical vary. Nonetheless, the weather of the vector z have a complementary worth. It’s apparent that element-wise operations are utilized to z and (1-z).
Generally we perceive issues by analyzing the intense instances. In an excessive state of affairs, let’s suppose that z is a vector of ones. What does that imply?
Merely, it signifies that the enter can be ignored, so the subsequent hidden state would be the earlier one! Within the reverse case that z can be a zero-element vector, it might imply that the earlier hidden state is nearly ignored. It can be crucial that I exploit the phrase nearly as a result of the replace vector n is affected by the earlier hidden state after the reset vector is utilized. Nonetheless, the recurrence can be nearly gone!
Intuitively, the shared vector z balances complementary the affect of the earlier hidden state and the replace enter vector n. Now, it turns into profound why I selected to make use of the world shared for z. All of the above will be illustrated within the following picture from Wikipedia:

Supply: By Jeblad – Personal work, CC BY-SA 4.0, borrowed from Wikipedia
The rationale that I’m not a giant fan of those diagrams, nevertheless, is that it could be complicated. It’s because they are often interpreted with scalar inputs x and h, which is no less than deceptive. The second is that it isn’t clear the place the trainable matrices are. Mainly, if you assume by way of these diagrams in your RNN journey, attempt to assume that x and h are multiplied by a weight matrix each time they’re used. Personally, I choose to dive into the equations. Luckily, the maths by no means lie!
Briefly, the reset gate (r vector) determines tips on how to fuse new inputs with the earlier reminiscence, whereas the replace gate defines how a lot of the earlier reminiscence stays.
That is all that you must know in order to know in-depth how GRU cells work. The best way they’re linked is strictly the identical as LSTM. The hidden output vector would be the enter vector to the subsequent GRU cell/layer. A bidirectional might be outlined by concurrently processing the sequence in an inverse method and concatenating the hidden vectors. By way of time unrolling in a single cell, the hidden output of the present timestep t turns into the earlier timestep within the subsequent one t+1.
LSTM VS GRU cells: Which one to make use of?
The GRU cells have been launched in 2014 whereas LSTM cells in 1997, so the trade-offs of GRU aren’t so totally explored. In lots of duties, each architectures yield comparable efficiency [1]. It’s typically the case that the tuning of hyperparameters could also be extra essential than selecting the suitable cell. Nonetheless, it’s good to check them facet by facet. Listed below are the essential 5 dialogue factors:
-
It is very important say that each architectures have been proposed to deal with the vanishing gradient downside. Each approaches are using a special manner of fusing earlier timestep info with gates to forestall from vanishing gradients. Nonetheless, the gradient move in LSTM’s comes from three completely different paths (gates), so intuitively, you’d observe extra variability within the gradient descent in comparison with GRUs.
-
If you need a extra quick and compact mannequin, GRU’s may be the selection, since they’ve fewer parameters. Thus, in a variety of functions, they are often skilled quicker. In small-scale datasets with not too large sequences, it is not uncommon to go for GRU cells since with fewer information the expressive energy of LSTM is probably not uncovered. On this perspective, GRU is taken into account extra environment friendly by way of less complicated construction.
-
Then again, if it’s a must to cope with giant datasets, the higher expressive energy of LSTMs could result in superior outcomes. In concept, the LSTM cells ought to keep in mind longer sequences than GRUs and outperform them in duties requiring modeling long-range correlations.
-
Based mostly on the equations, one can observe that a GRU cell has one much less gate than an LSTM. Exactly, only a reset and replace gates as an alternative of the neglect, enter, and output gate of LSTM.
-
Mainly, the GRU unit controls the move of data with out having to make use of a cell reminiscence unit (represented as c within the equations of the LSTM). It exposes the entire reminiscence (in contrast to LSTM), with none management. So, it’s primarily based on the duty at hand if this may be useful.
To summarize, the reply lies within the information. There may be no clear winner to state which one is healthier. The one manner to make sure which one works finest in your downside is to coach each and analyze their efficiency. To take action, you will need to construction your deep studying venture in a versatile method. Aside from the cited papers, please notice that as a way to accumulate and merge all these pin-out factors I suggested this and this.) hyperlinks.
Conclusion
On this article, we offered a overview of the GRU unit. We noticed it’s distinct traits and we even constructed our personal cell that was used to foretell sine sequences. In a while, we in contrast facet to facet LSTM’s and GRU’s. This time, we are going to suggest for additional studying an attention-grabbing paper that analyzes GRUs and LSTMs within the context of pure language processing [3] by Yin et al. 2017. As a ultimate RNN useful resource, we offer this video with a number of visualizations that you could be discovered helpful:
Remember the fact that there isn’t any single useful resource to cowl all of the features of understanding RNN’s, and completely different people be taught in a special method. Our mission is to supply 100% unique content material within the respect that we give attention to the below the hood understanding of RNN’s, fairly than deploying their applied layers in a extra fancy utility.
Keep tuned for extra tutorials.
@article{adaloglou2020rnn,
title = "Intuitive understanding of recurrent neural networks",
writer = "Adaloglou, Nikolas and Karagiannakos, Sergios ",
journal = "https://theaisummer.com/",
12 months = "2020",
url = "https://theaisummer.com/gru"
}
References
[1] Greff, Okay., Srivastava, R. Okay., Koutník, J., Steunebrink, B. R., & Schmidhuber, J. (2016). LSTM: A search house odyssey. IEEE transactions on neural networks and studying programs, 28(10), 2222-2232.
[2] Chung, J., Gulcehre, C., Cho, Okay., & Bengio, Y. (2014). Empirical analysis of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555.
[3] Yin, W., Kann, Okay., Yu, M., & Schütze, H. (2017). Comparative research of cnn and rnn for pure language processing. arXiv preprint arXiv:1702.01923.
[4] Esteban, C., Hyland, S. L., & Rätsch, G. (2017). Actual-valued (medical) time collection technology with recurrent conditional gans. arXiv preprint arXiv:1706.02633.
[5] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Consideration is all you want. In Advances in neural info processing programs (pp. 5998-6008).
[6] Hannun, “Sequence Modeling with CTC”, Distill, 2017.

* Disclosure: Please notice that a few of the hyperlinks above may be affiliate hyperlinks, and at no extra price to you, we are going to earn a fee in case you determine to make a purchase order after clicking by means of.

