Scalability is definitely a high-level downside that we are going to all be thrilled to have. Reaching a degree the place we have to incorporate extra machines and sources to deal with the visitors coming into our deep studying algorithm, is a dream come true for a lot of startups.
Nonetheless many engineering groups do not pay the mandatory consideration to it. The principle cause: they do not have a transparent plan on the way to scale issues up from the start. And that is completely fantastic! As a result of we first have to concentrate on optimizing our software and our mannequin, and cope with all that stuff later. Nevertheless it wouldn’t harm us to have a transparent plan from the beginning.
On this article, we are going to comply with together with a small AI startup on its journey to scale from 1 to tens of millions of customers. We’ll talk about what’s a typical course of to deal with a gentle development within the consumer base, and what instruments and strategies one can incorporate. And naturally, we are going to discover scalability from a machine studying perspective. We’ll see how issues differentiate from frequent software program and what novel issues come up.
So we could say that we have now a Deep Studying mannequin that performs segmentation on a picture. We prepare it, we optimize the information processing pipeline, we construct a typical internet software round it, and now it is time to deploy it.
So what’s our subsequent step right here?
At this level, we have now principally two choices. The primary is to arrange our personal server, host it there, and fear about all of the scalability issues as we develop. Ideally we are able to deploy the appliance in a cloud supplier and benefit from all of the ready-to-use infrastructure. I’ll assume that you’ll go along with the second choice. If you happen to select the primary one, I significantly wish to know why!
For example that we picked Google Cloud as our supplier, we opened an account, arrange a challenge and we’re able to go.
We could?
There’s a nice discuss taking place yearly within the AWS convention the place they current the way to scale an software from 1 to 10 million customers exploring all of the completely different AWS methods that we are able to use alongside the method. This text is closely impressed by it but it surely focuses on machine studying functions as an alternative of plain software program.
Word that I’ll use Google Cloud parts for instance the completely different architectures however the identical rules apply to different cloud computing companies similar to AWS or Azure. For many who are unfamiliar with Google Cloud Providers (GCS), I’ll depart a glossary part on the finish outlining the used parts.

First deployment of the Machine Studying app
As we mentioned in a earlier article, a VM occasion is nothing greater than a devoted computing system hosted on Google cloud.
Step one can be to create a VM occasion on Google cloud’s compute engine. We copy the entire challenge, permit HTTP visitors, and join our area title to it. And that is it. The mannequin is up and working and is seen to customers by way of our area. Individuals are beginning to ship requests, every part works as anticipated, the system stays extremely responsive, the mannequin’s accuracy appears to be on good ranges.
And we’re extremely comfortable about it.

So we have now a monolithic app hosted in a single digital machine which requires a little bit of handbook work to deploy new modifications and restart the service. Nevertheless it’s not dangerous. After doing that for just a few weeks nevertheless, some issues are beginning to come up.
-
Deployments require an excessive amount of handbook work
-
Dependencies are beginning to get out of sync as we add new library variations and new fashions
-
Debugging is just not easy.
To unravel a few of these issues, we add a brand new CI/CD pipeline and we handle to automate issues like constructing, testing, and deployment.
Steady integration (CI) and Steady deployment (CD) is a set of practices and pipelines that automates the constructing, testing, and deployment course of. Well-known frameworks embrace Jenkins and CircleCI however for instance’s sake, we’ll use the Cloud Construct element from GCS.
We additionally add some logs so we are able to entry the occasion and uncover what’s unsuitable. Maybe we are able to even migrate from a fundamental Digital machine to a Deep Studying particular VM which is optimized for Deep Studying functions. It comes with Tensorflow, CUDA, and different essential stuff preinstalled, serving to us alleviate a few of the handbook work.

However deployment and dependencies are nonetheless a problem. So we wrap the appliance inside a docker container, put it within the VM and we’re good to go. Once more, we are able to use a ready-to-use Deep Studying particular container. Consequently, each time we have to add a brand new library model or a brand new mannequin, we alter the Dockerfile, rebuild the container, and redeploy. Issues are wanting good as soon as extra.
After some time, the app is beginning to develop into fashionable. Increasingly customers are becoming a member of, and the VM occasion is beginning to battle: response occasions go up, {hardware} utilization is at very excessive ranges.
I am afraid that we have now to scale.
Vertical vs horizontal scaling
Vertical scaling (scaling-up) is after we add extra energy (CPU, Reminiscence, GPU) to an current machine to deal with the visitors.
Our first response is to scale vertically. After some time, the occasion is struggling once more. We then create a good greater one. After doing that a few occasions, we’re beginning to hit a restrict and notice that we are able to’t preserve scaling up.

Consequently, we have now to scale out.
Horizontal scaling (scaling out) is when we add extra machines to the community and share the processing and reminiscence workload throughout them.
This merely means: create a brand new VM occasion! We’ll then replicate the appliance and have them each run and serve visitors concurrently.
However how can we resolve which occasion to ship the requests to? How can we preserve the visitors even between them? That is the place load balancers come into the sport.
A load balancer is a tool that distributes community visitors throughout a number of machines and ensures that no single server bears an excessive amount of load, by spreading the visitors. Subsequently, it will increase the capability, reliability, and availability of the system.

After together with a second occasion and a load balancer, the visitors is dealt with completely. Neither occasion is struggling and their response occasions return down.
Scaling out
The wonderful thing about this structure is that it may possibly take us a good distance down the street. Actually, it’s in all probability what most of us will ever want. As visitors grows, we are able to preserve including increasingly cases and cargo steadiness the visitors between them. We are able to even have cases in several geographic areas ( or availability zones as AWS calls them) to attenuate the response time in all components of the world.
Fascinating truth: we do not have to fret concerning the load balancer! As a result of most cloud suppliers similar to GCS provide load balancers that scale requests amongst a number of areas.

Load balancers additionally present strong safety. They entail encryption/decryption, consumer authentication, well being connections checks. There even have capabilities for monitoring and debugging.
Recap
Thus far, we managed to make sure availability and reliability utilizing load balancers and a number of cases. In parallel, we alleviate the ache of deployments with containers and CI/CD, and we have now a fundamental type of logging and monitoring.
I’d say that we’re in fairly fine condition.
Once more, within the overwhelming majority of use circumstances, this structure is 100% sufficient. However there are occasions when sure unpredictable issues can happen. A quite common instance is sudden spikes in visitors.
Generally we may even see very huge will increase within the incoming requests. Perhaps it is Black Friday and other people need to store or we’re in the course of a lockdown and so they all surf the online. And belief me it’s extra frequent than you might need to imagine.
What’s the plan of action right here?
One may assume that we are able to enhance the capability of our machines beforehand. On this manner, we are able to deal with the spikes within the request charge. However that might be an enormous quantity of unused sources. And most significantly: cash not effectively spent.
The answer to such issues? Autoscaling.
Autoscaling
Autoscaling is a technique utilized in cloud computing that alters the variety of computational sources primarily based on the load. Sometimes which means the variety of cases goes up or down routinely, primarily based on some metrics.
Autoscaling comes into 2 most important varieties: scheduled scaling and dynamic scaling.
In scheduled scaling, we all know upfront that the visitors will range in a selected time period. To deal with this, we manually instruct the system to create extra cases throughout this time.
Dynamic scaling, then again, screens some predefined metrics and scales the cases after they surpass a restrict. These metrics can embrace issues like CPU or Reminiscence utilization, requests depend, response time, and extra. For instance, we are able to configure our variety of cases to double when the variety of requests is greater than 100. When the requests fall once more, the cases will return to their regular state.
And that effectively solves the random spikes concern. Yet another field checked for our software.
Caching
One other nice solution to decrease the response time of our software is to make use of some type of caching mechanism. Generally we may even see many equivalent requests coming in (though this hardly ever would be the case for pc imaginative and prescient apps). If that is the case, we are able to keep away from hitting our cases many occasions and we are able to cache the response of the primary request and ship it to all the opposite customers.
A cache is nothing greater than a storage system that saves knowledge in order that future requests might be served quicker
An vital factor to know right here is that we have now to calibrate our caching mechanism effectively in an effort to keep away from two issues: both caching an excessive amount of knowledge that won’t be used steadily or maintaining the cache idle for a really very long time.

Monitoring alerts
One of the crucial vital and truthfully most annoying components of an software that is been served to tens of millions of customers is alerts. Generally issues crash. Perhaps there was a bug within the code, or the auto-scaling system didn’t work, or there was a community failure, or some energy outage happens (there are actually 100 issues that may go unsuitable). If our software serves just a few customers, this may not be that important. However within the case the place we serve tens of millions of them, each minute our app is down we’re dropping cash.
That is why we should have an alerting system in place, so we are able to leap as shortly as potential and repair the error. Being on-call is an integral a part of being a software program engineer (in my very own opinion is the worst half). This is applicable to machine studying engineers too. Though a few of the time, in real-life initiatives that’s not the case. However machine studying fashions can have bugs as effectively and they’re affected by all of the aforementioned issues.
No have to construct a customized resolution. Most cloud suppliers present monitoring methods that 1) monitor varied predefined metrics 2) allow visualizations and dashboards for us to test their progress over time and three) notify us when an incident occurs.

A monitoring system mixed with logging and an error reporting module is all we have to sleep effectively at night time. So I extremely advocate incorporating such mechanisms in your machine studying software.
Up till this level of the article, many of the ideas talked about apply to every kind of software program. That’s why any longer we are going to see some examples which can be wanted just for machine studying functions. Though the instruments that we are going to use will not be particular to ML, the ideas and the issues behind them are distinctive within the area.
We have put numerous effort up to now to maintain the appliance scalable and I believe we are able to say that we have achieved a reasonably good job. And I dare to say that we would be capable to scale to tens of millions of customers. However most machine studying functions have another wants and issues to unravel.
Retraining Machine Studying Fashions
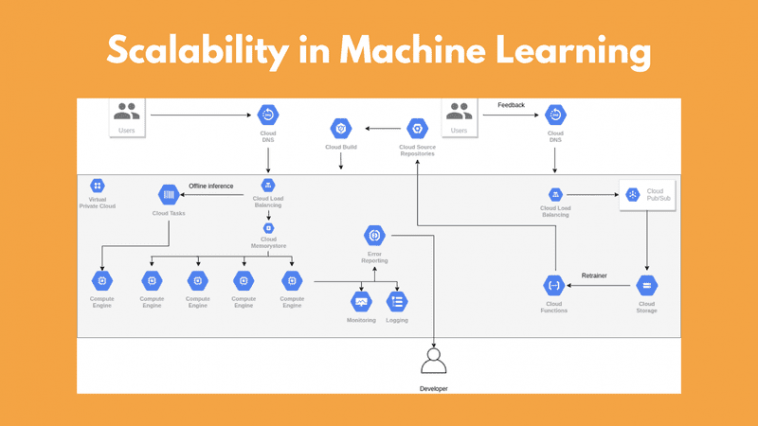
As time passes and the mannequin serves increasingly customers, the information distribution is beginning to shift. Consequently, the mannequin’s accuracy is step by step falling down. It’s merely inevitable and it occurs to most machine studying functions. Thus, we have to construct a loop to retrain the mannequin with new knowledge and redeploy it as a brand new model. We are able to discover the information from an exterior supply, however generally this is not potential. That’s why we must always be capable to use inner knowledge.
With our present structure, this isn’t possible as we do not retailer any predictions or suggestions. To begin with, we have to discover a manner to get again suggestions from our customers and use them as labels in our retraining. Which means that we are going to want an endpoint that purchasers ship their suggestions associated to a selected prediction.
If we assume that we have now that in place, the subsequent step is to retailer the information. We’d like a database. Right here we have now many options and it’s a quite common debate between groups. Most scalability specialists will declare that we must always begin with a SQL database and transfer to a NoSQL when the viewers grows to a selected level. Though that is true in 95% of the circumstances, somebody might argue that machine studying is just not one among them. As a result of machine studying knowledge are unstructured and so they cannot be organized within the type of tables.

From a scalability perspective each SQL and NoSQL can deal with a reasonably large quantity of knowledge with NoSQL having a slight benefit within the space. I am not gonna go into many particulars right here about how scalability works on databases, however I’ll point out some fundamental ideas for individuals who need to look into them.
For SQL of us, we have now strategies similar to master-slave replication, sharding, denormalization, federation whereas for NoSQL the scalability patterns are customized to the precise database sort (key-value, doc, column-based, graph).
The essential factor is that we now have the information saved. Consequently, we are able to begin constructing coaching jobs by feeding the endured knowledge into the mannequin. The brand new mannequin can be deployed into manufacturing changing the outdated one. And we are able to repeat this course of in response to our wants.
Two issues to notice right here:
-
The mannequin versioning downside is already solved by containers as a result of we are able to create a brand new picture from the brand new mannequin and deploy it.
-
The storage of the mannequin weights can also be solved. Both through the use of the database or ideally with an object storage service (similar to google cloud storage) which might be extraordinarily scalable and environment friendly.
Nonetheless, the issue of working a number of, high-intensive, simultaneous jobs stays. As regular, we have now completely different options.
-
We are able to spin up new cases/containers on demand, run the roles, and take away them after completion.
-
We are able to additionally use a distributed knowledge processing framework similar to Hadoop or Spark. These frameworks are capable of deal with huge quantities of knowledge and scale effectively throughout completely different machines.
Most huge knowledge processing frameworks are primarily based on some type of the map-reduce paradigm. Map-reduce is a distributed algorithm that works as follows: We first purchase the information in many alternative chunks, execute a processing step on each (one) after which mix the outcomes right into a single dataset (cut back). As you’ll be able to think about this technique is extremely scalable and it may possibly deal with huge quantities of knowledge.

Supply: A BIG DATA PROCESSING FRAMEWORK BASED ON MAPREDUCE WITH APPLICATION TO INTERNET OF THINGS
Mannequin A/B testing
One other want that it would seem, particularly after having retraining in place, is mannequin A/B testing. A/B testing refers back to the means of making an attempt out completely different fashions in manufacturing by sending completely different a great deal of visitors into every one among them. Once more, Docker solves this concern out of the field, as a result of it allows us to deploy completely different containers on the identical time. To distribute the visitors, we are able to configure the load balancer to ship the requests accordingly. For instance, we are able to ship solely 5% of the visitors into the brand new mannequin and preserve the opposite 95% for the outdated one.
Offline inference
Final however not least we have now offline inferences. Predicting in real-time is just not at all times possible or desired. There are many use circumstances when the mannequin merely cannot infer in a few seconds or our software doesn’t want an instantaneous response. In these circumstances, the choice is to have an offline inference pipeline and predict in an asynchronous method.
Asynchronicity signifies that the consumer will not have to attend for the mannequin’s response. He can be notified later concerning the completion of the prediction (or not notified in any respect). However how can we construct such pipelines?
The most typical strategy is process/message queues.
A message queue is a type of asynchronous service to service communication. A queue shops messages coming from a producer and ensures that every one can be processed solely as soon as by a single client. A message queue can have a number of customers and producers.

Google cloud Pub/Sub. Supply: enterpriseintegrationpatterns.com
In our case, a producer can be an occasion that receives the inference request and sends it to a employee. The employees will execute the inference primarily based on the despatched options. As an alternative of sending the messages on to the employee (aka the buyer), it should ship it to a message queue. The message queue receives messages from completely different producers and sends them to completely different customers. However why do we’d like a queue?
Just a few traits that make message queues ideally suited are:
-
They be sure that the message will at all times be consumed
-
They are often scaled nearly effortlessly by including extra cases
-
They function asynchronously
-
They decouple the buyer from the producer
-
They attempt to preserve the order of messages
-
They supply the power to prioritize duties.

An offline inference pipeline might be executed both in batches or one-by-one. In each circumstances, we are able to use message queues. Nonetheless, within the case of batching, we also needs to have a system that mixes many inferences collectively and ship them again to the proper consumer. Batches can occur both on the occasion stage or on the service stage.
And that formally ends our scalability journey. To any extent further, all we are able to do is fine-tune the appliance. Options embrace:
-
Splitting performance into completely different companies by constructing a microservices structure
-
Analyzing in-depth all the stack and optimizing wherever it’s potential.
-
As a final resort, we are able to begin constructing customized options.
However by then, we could have no less than 1 million {dollars} in income so issues are wanting good.
Wrap up
On this arguably lengthy put up, I attempted to provide an outline of how firms’ infrastructure evolves over time as they develop and purchase extra customers. Scaling an software is by any means a simple endeavor, and it turns into much more tough for machine studying methods. The principle cause is that they introduce a complete new set of issues that aren’t current in frequent software program.
The enjoyable half is that I did not even start to cowl all the spectrum of options and issues. However that might be unattainable for a single article (or perhaps a single guide). I do additionally know that some could have difficulties greedy all of the completely different methods and terminology. Nonetheless, I hope that this put up will act as a information that will help you perceive the fundamentals and go from there to discover and dive deep into the varied architectures and strategies.
To proceed from right here, I strongly advocate the MLOps (Machine Studying Operations) Fundamentals course provided by Google cloud
Lastly, it’s price mentioning that this text is a part of the deep studying in manufacturing collection. Thus far, we took a easy Jupyter pocket book, we transformed it to extremely performant code, we educated it, and now it is time to deploy it within the cloud and serve it to 2 customers.
That is why I wished to put in writing this overview earlier than we proceed with the deployment. In order that all of us can have a transparent thought of what lies forward in real-life initiatives. If you need to comply with together with the collection, remember to subscribe to our publication. It is already the 13th article and I do not see us stopping anytime quickly. Subsequent time we are going to dive into Kubernetes so keep tuned…
Addio …
Glossary
* Disclosure: Please observe that a few of the hyperlinks above is likely to be affiliate hyperlinks, and at no extra value to you, we are going to earn a fee in case you resolve to make a purchase order after clicking by way of.
